 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA One-step Pruning-recovery Framework for Acceleration of Convolutional Neural Networks
Paper and Code
Jun 18, 2019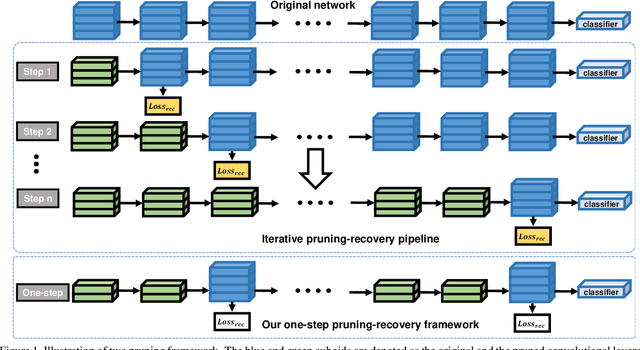
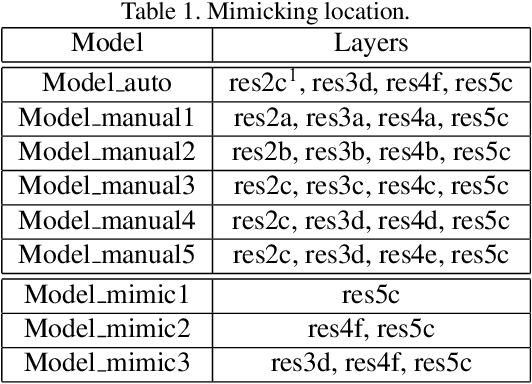
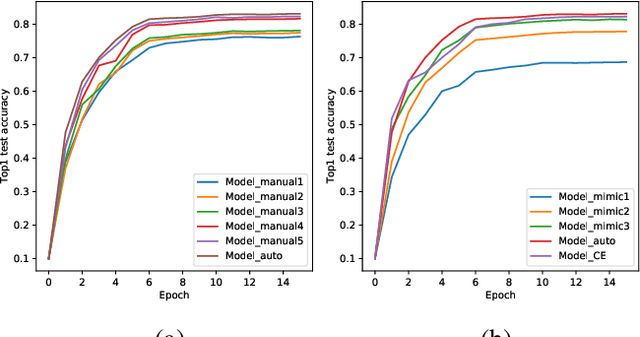
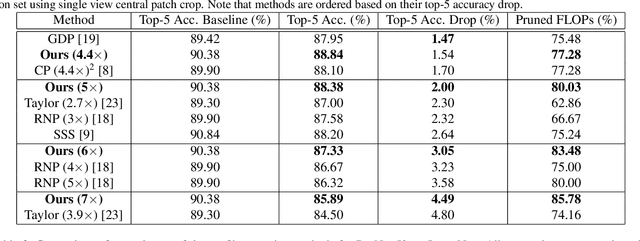
Acceleration of convolutional neural network has received increasing attention during the past several years. Among various acceleration techniques, filter pruning has its inherent merit by effectively reducing the number of convolution filters. However, most filter pruning methods resort to tedious and time-consuming layer-by-layer pruning-recovery strategy to avoid a significant drop of accuracy. In this paper, we present an efficient filter pruning framework to solve this problem. Our method accelerates the network in one-step pruning-recovery manner with a novel optimization objective function, which achieves higher accuracy with much less cost compared with existing pruning methods. Furthermore, our method allows network compression with global filter pruning. Given a global pruning rate, it can adaptively determine the pruning rate for each single convolutional layer, while these rates are often set as hyper-parameters in previous approaches. Evaluated on VGG-16 and ResNet-50 using ImageNet, our approach outperforms several state-of-the-art methods with less accuracy drop under the same and even much fewer floating-point operations (FLOPs).