 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Adversarial Training and Disentangled Speech Representation for Robust Zero-Resource Subword Modeling
Paper and Code
Aug 09, 2019
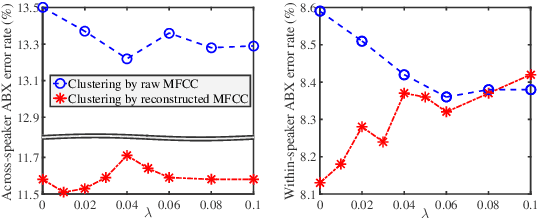
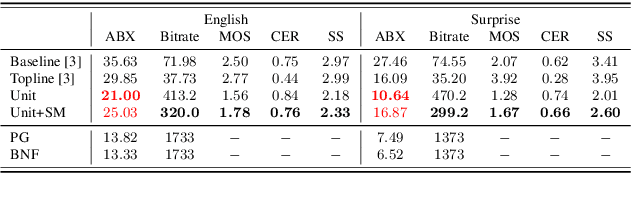
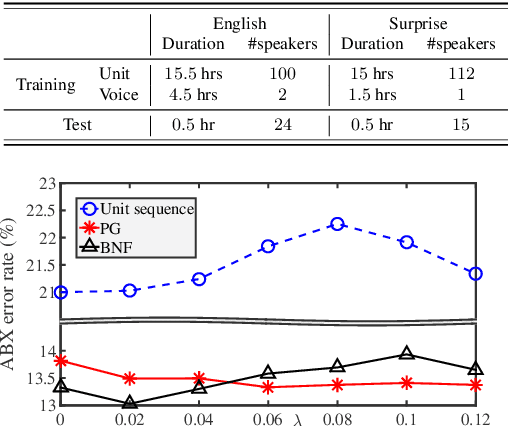
This study addresses the problem of unsupervised subword unit discovery from untranscribed speech. It forms the basis of the ultimate goal of ZeroSpeech 2019, building text-to-speech systems without text labels. In this work, unit discovery is formulated as a pipeline of phonetically discriminative feature learning and unit inference. One major difficulty in robust unsupervised feature learning is dealing with speaker variation. Here the robustness towards speaker variation is achieved by applying adversarial training and FHVAE based disentangled speech representation learning. A comparison of the two approaches as well as their combination is studied in a DNN-bottleneck feature (DNN-BNF) architecture. Experiments are conducted on ZeroSpeech 2019 and 2017. Experimental results on ZeroSpeech 2017 show that both approaches are effective while the latter is more prominent, and that their combination brings further marginal improvement in across-speaker condition. Results on ZeroSpeech 2019 show that in the ABX discriminability task, our approaches significantly outperform the official baseline, and are competitive to or even outperform the official topline. The proposed unit sequence smoothing algorithm improves synthesis quality, at a cost of slight decrease in ABX discriminability.