 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding the Needle in the Haystack with Convolutions: on the benefits of architectural bias
Paper and Code
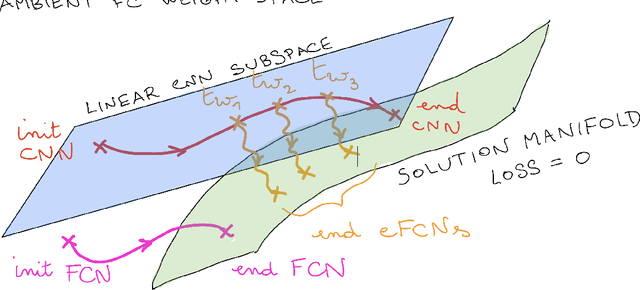
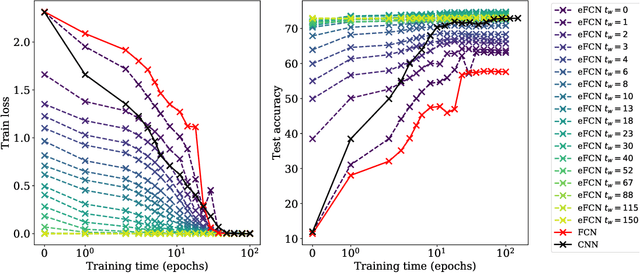
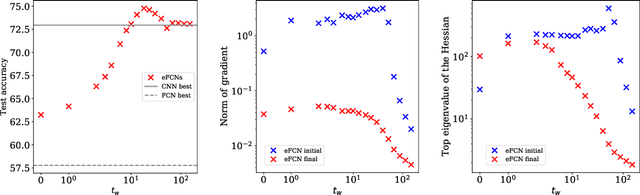
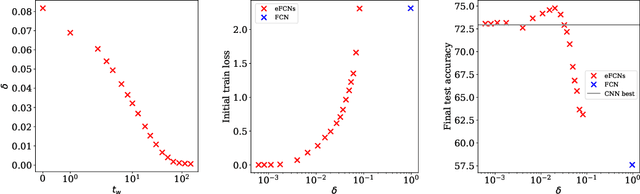
Despite the phenomenal success of deep neural networks in a broad range of learning tasks, there is a lack of theory to understand the way they work. In particular, Convolutional Neural Networks (CNNs) are known to perform much better than Fully-Connected Networks (FCNs) on spatially structured data: the architectural structure of CNNs benefits from prior knowledge on the features of the data, for instance their translation invariance. The aim of this work is to understand this fact through the lens of dynamics in the loss landscape. We introduce a method that maps a CNN to its equivalent FCN (denoted as eFCN). Such an embedding enables the comparison of CNN and FCN training dynamics directly in the FCN space. We use this method to test a new training protocol, which consists in training a CNN, embedding it to FCN space at a certain 'switch time' $t_w$, then resuming the training in FCN space. We observe that for all switch times, the deviation from the CNN subspace is small, and the final performance reached by the eFCN is higher than that reachable by the standard FCN. More surprisingly, for some intermediate switch times, the eFCN even outperforms the CNN it stemmed from. The practical interest of our protocol is limited by the very large size of the highly sparse eFCN. However, it offers an interesting insight into the persistence of the architectural bias under the stochastic gradient dynamics even in the presence of a huge number of additional degrees of freedom. It shows the existence of some rare basins in the FCN space associated with very good generalization. These can be accessed thanks to the CNN prior, and are otherwise missed.