 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Word Embeddings with Domain Awareness
Paper and Code
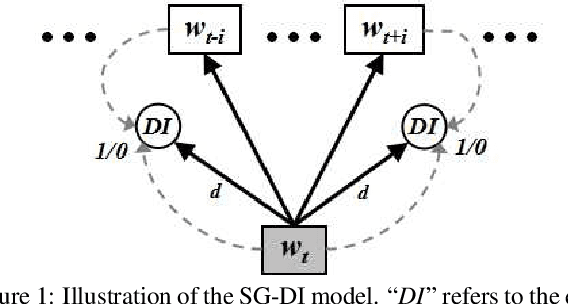
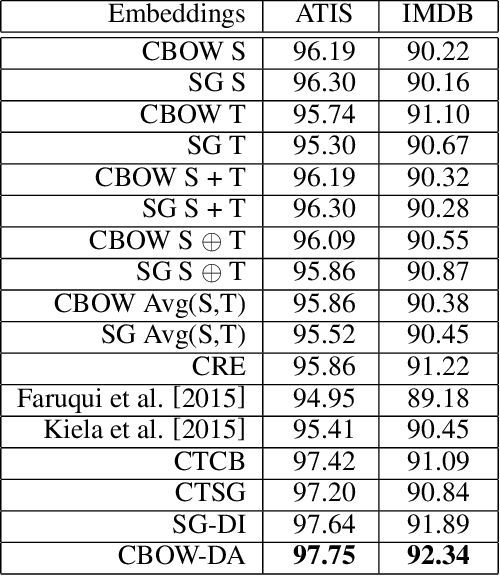
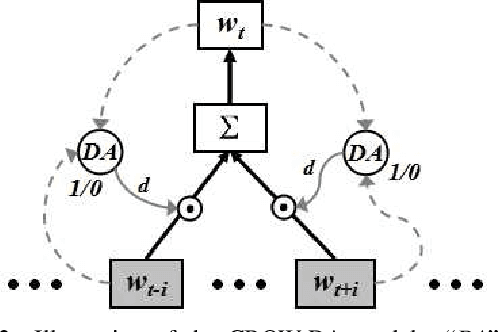
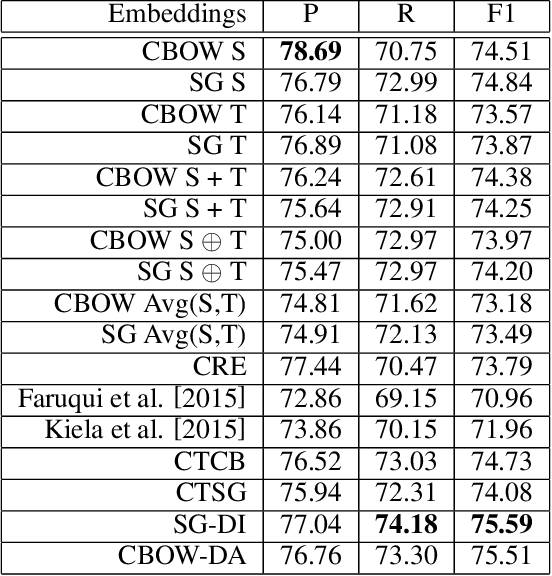
Word embeddings are traditionally trained on a large corpus in an unsupervised setting, with no specific design for incorporating domain knowledge. This can lead to unsatisfactory performances when training data originate from heterogeneous domains. In this paper, we propose two novel mechanisms for domain-aware word embedding training, namely domain indicator and domain attention, which integrate domain-specific knowledge into the widely used SG and CBOW models, respectively. The two methods are based on a joint learning paradigm and ensure that words in a target domain are intensively focused when trained on a source domain corpus. Qualitative and quantitative evaluation confirm the validity and effectiveness of our models. Compared to baseline methods, our method is particularly effective in near-cold-start scenarios.