 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Caesar Cipher to Unsupervised Learning: A New Method for Classifier Parameter Estimation
Paper and Code
Jun 06, 2019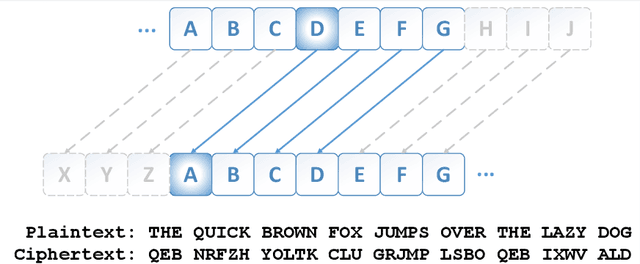

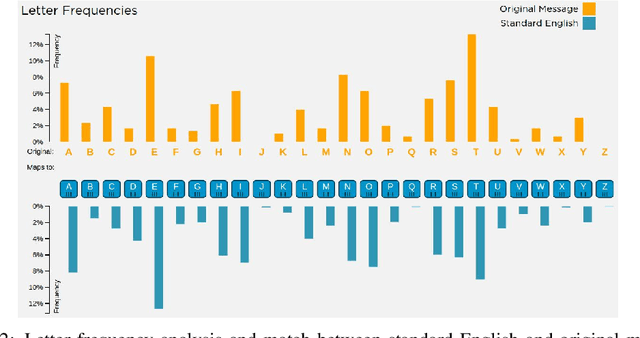
Many important classification problems, such as object classification, speech recognition, and machine translation, have been tackled by the supervised learning paradigm in the past, where training corpora of parallel input-output pairs are required with high cost. To remove the need for the parallel training corpora has practical significance for real-world applications, and it is one of the main goals of unsupervised learning. Recently, encouraging progress in unsupervised learning for solving such classification problems has been made and the nature of the challenges has been clarified. In this article, we review this progress and disseminate a class of promising new methods to facilitate understanding the methods for machine learning researchers. In particular, we emphasize the key information that enables the success of unsupervised learning - the sequential statistics as the distributional prior in the labels. Exploitation of such sequential statistics makes it possible to estimate parameters of classifiers without the need of paired input-output data. In this paper, we first introduce the concept of Caesar Cipher and its decryption, which motivated the construction of the novel loss function for unsupervised learning we use throughout the paper. Then we use a simple but representative binary classification task as an example to derive and describe the unsupervised learning algorithm in a step-by-step, easy-to-understand fashion. We include two cases, one with Bigram language model as the sequential statistics for use in unsupervised parameter estimation, and another with a simpler Unigram language model. For both cases, detailed derivation steps for the learning algorithm are included. Further, a summary table compares computational steps of the two cases in executing the unsupervised learning algorithm for learning binary classifiers.