 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Intrinsic Robustness of Stochastic Bandits to Strategic Manipulation
Paper and Code
Jun 04, 2019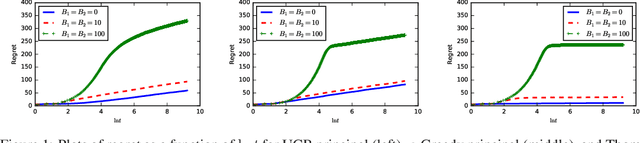

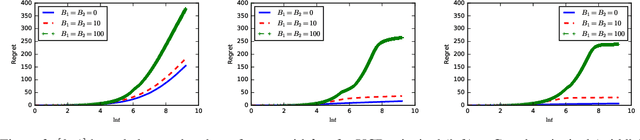
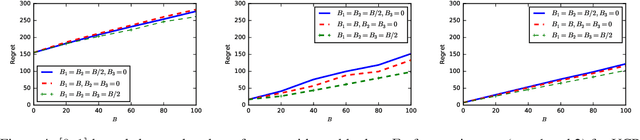
We study the behavior of stochastic bandits algorithms under \emph{strategic behavior} conducted by rational actors, i.e., the arms. Each arm is a strategic player who can modify its own reward whenever pulled, subject to a cross-period budget constraint. Each arm is \emph{self-interested} and seeks to maximize its own expected number of times of being pulled over a decision horizon. Strategic manipulations naturally arise in various economic applications, e.g., recommendation systems such as Yelp and Amazon. We analyze the robustness of three popular bandit algorithms: UCB, $\varepsilon$-Greedy, and Thompson Sampling. We prove that all three algorithms achieve a regret upper bound $\mathcal{O}(\max \{ B, \ln T\})$ under \emph{any} (possibly adaptive) strategy of the strategic arms, where $B$ is the total budget across arms. Moreover, we prove that our regret upper bound is \emph{tight}. Our results illustrate the intrinsic robustness of bandits algorithms against strategic manipulation so long as $B=o(T)$. This is in sharp contrast to the more pessimistic model of adversarial attacks where an attack budget of $\mathcal{O}(\ln T) $ can trick UCB and $\varepsilon$-Greedy to pull the optimal arm only $o(T)$ number of times. Our results hold for both bounded and unbounded rewards.