 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Adaptation of Pretrained Transformers for Abstractive Summarization
Paper and Code
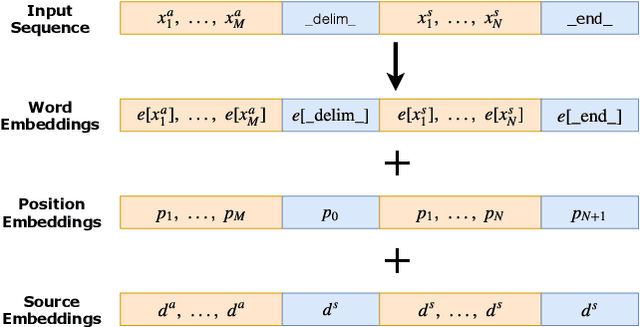

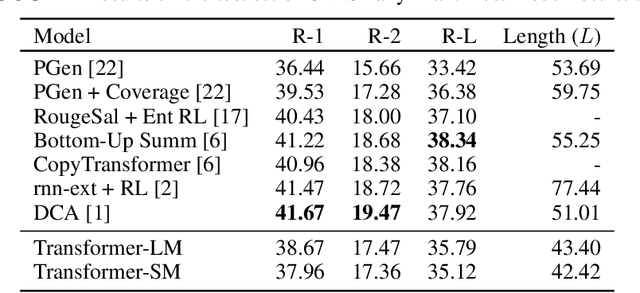
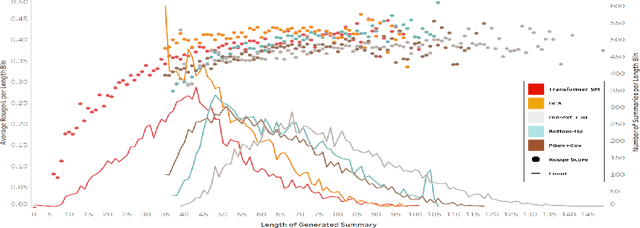
Large-scale learning of transformer language models has yielded improvements on a variety of natural language understanding tasks. Whether they can be effectively adapted for summarization, however, has been less explored, as the learned representations are less seamlessly integrated into existing neural text production architectures. In this work, we propose two solutions for efficiently adapting pretrained transformer language models as text summarizers: source embeddings and domain-adaptive training. We test these solutions on three abstractive summarization datasets, achieving new state of the art performance on two of them. Finally, we show that these improvements are achieved by producing more focused summaries with fewer superfluous and that performance improvements are more pronounced on more abstractive datasets.