 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Aligned Representation Learning for Person Re-identification
Paper and Code

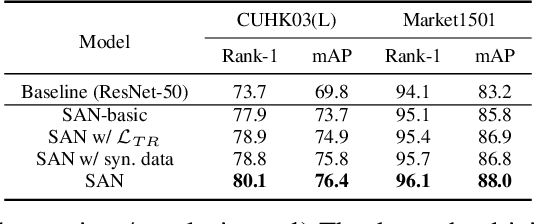
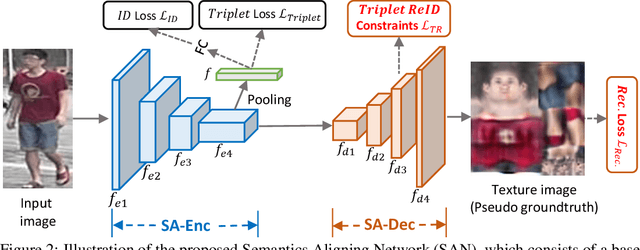
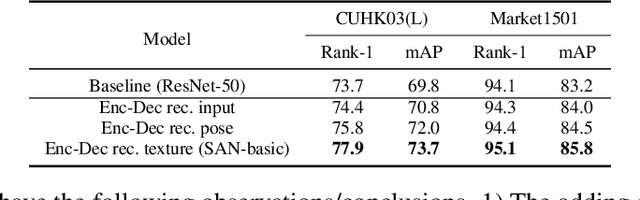
Person re-identification (reID) aims to match person images to retrieve the ones with the same identity. This is a challenging task, as the images to be matched are generally semantically misaligned due to the diversity of human poses and capture viewpoints, incompleteness of the visible bodies (due to occlusion), etc. In this paper, we propose a framework that drives the reID network to learn semantics-aligned feature representation through delicate supervision designs. Specifically, we build a Semantics Aligning Network (SAN) which consists of a base network as encoder (SA-Enc) for re-ID, and a decoder (SA-Dec) for reconstructing/regressing the densely semantics aligned full texture image. We jointly train the SAN under the supervisions of person re-identification and aligned texture generation. Moreover, at the decoder, besides the reconstruction loss, we add triplet reID constraints/losses over the feature maps as the perceptual losses. The decoder is discarded in the inference/test and thus our scheme is computationally efficient. Ablation studies demonstrate the effectiveness of our design. We achieve the state-of-the-art performances on the benchmark datasets CUHK03, Market1501, MSMT17, and the partial person reID dataset Partial REID.