 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Novel Policies For Tasks
Paper and Code
May 13, 2019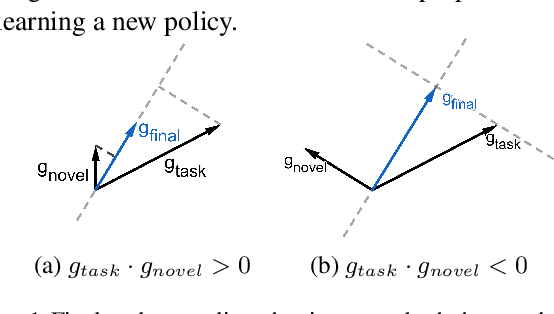

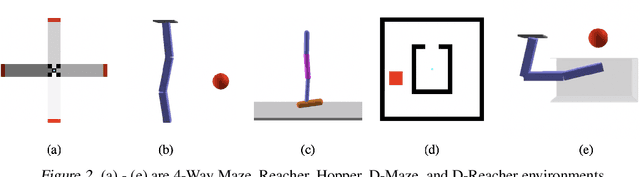
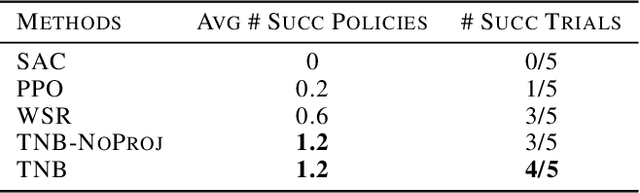
In this work, we present a reinforcement learning algorithm that can find a variety of policies (novel policies) for a task that is given by a task reward function. Our method does this by creating a second reward function that recognizes previously seen state sequences and rewards those by novelty, which is measured using autoencoders that have been trained on state sequences from previously discovered policies. We present a two-objective update technique for policy gradient algorithms in which each update of the policy is a compromise between improving the task reward and improving the novelty reward. Using this method, we end up with a collection of policies that solves a given task as well as carrying out action sequences that are distinct from one another. We demonstrate this method on maze navigation tasks, a reaching task for a simulated robot arm, and a locomotion task for a hopper. We also demonstrate the effectiveness of our approach on deceptive tasks in which policy gradient methods often get stuck.