 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying and Alleviating the Language Prior Problem in Visual Question Answering
Paper and Code
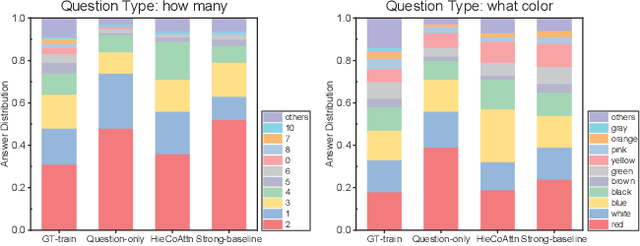
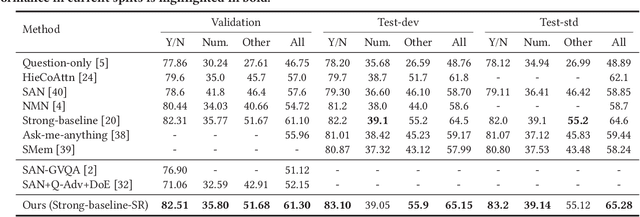
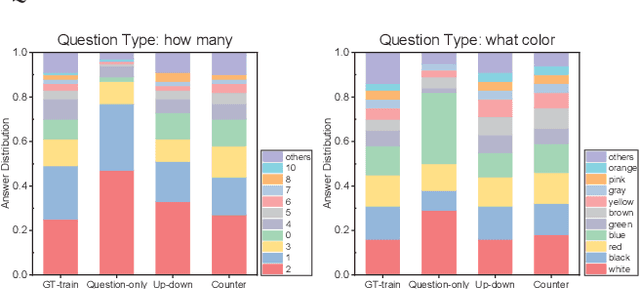
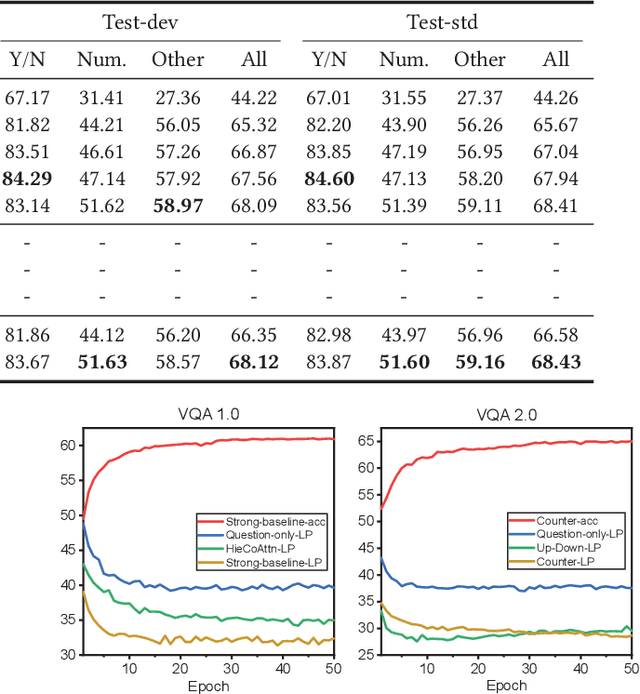
Benefiting from the advancement of computer vision, natural language processing and information retrieval techniques, visual question answering (VQA), which aims to answer questions about an image or a video, has received lots of attentions over the past few years. Although some progress has been achieved so far, several studies have pointed out that current VQA models are heavily affected by the \emph{language prior problem}, which means they tend to answer questions based on the co-occurrence patterns of question keywords (e.g., how many) and answers (e.g., 2) instead of understanding images and questions. Existing methods attempt to solve this problem by either balancing the biased datasets or forcing models to better understand images. However, only marginal effects and even performance deterioration are observed for the first and second solution, respectively. In addition, another important issue is the lack of measurement to quantitatively measure the extent of the language prior effect, which severely hinders the advancement of related techniques. In this paper, we make contributions to solve the above problems from two perspectives. Firstly, we design a metric to quantitatively measure the language prior effect of VQA models. The proposed metric has been demonstrated to be effective in our empirical studies. Secondly, we propose a regularization method (i.e., score regularization module) to enhance current VQA models by alleviating the language prior problem as well as boosting the backbone model performance. The proposed score regularization module adopts a pair-wise learning strategy, which makes the VQA models answer the question based on the reasoning of the image (upon this question) instead of basing on question-answer patterns observed in the biased training set. The score regularization module is flexible to be integrated into various VQA models.