 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Independent Subspace Clusterings
Paper and Code
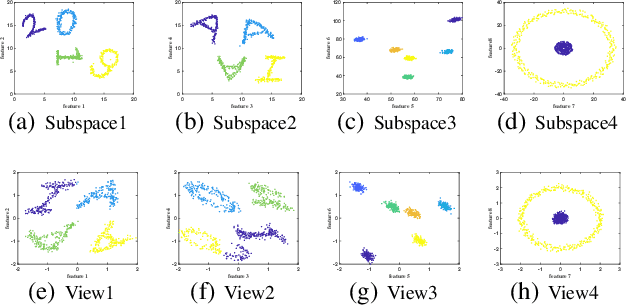
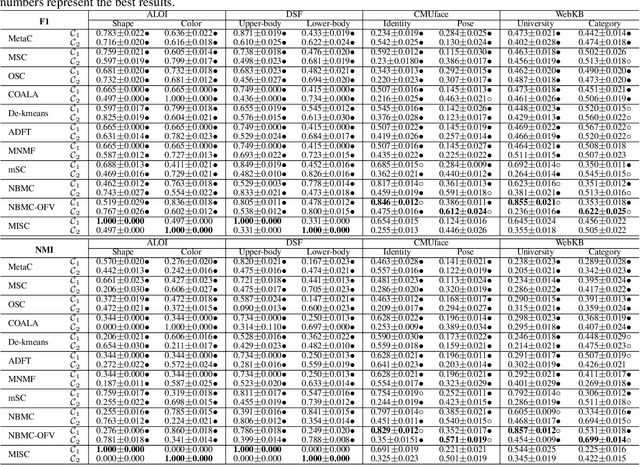


Multiple clustering aims at discovering diverse ways of organizing data into clusters. Despite the progress made, it's still a challenge for users to analyze and understand the distinctive structure of each output clustering. To ease this process, we consider diverse clusterings embedded in different subspaces, and analyze the embedding subspaces to shed light into the structure of each clustering. To this end, we provide a two-stage approach called MISC (Multiple Independent Subspace Clusterings). In the first stage, MISC uses independent subspace analysis to seek multiple and statistical independent (i.e. non-redundant) subspaces, and determines the number of subspaces via the minimum description length principle. In the second stage, to account for the intrinsic geometric structure of samples embedded in each subspace, MISC performs graph regularized semi-nonnegative matrix factorization to explore clusters. It additionally integrates the kernel trick into matrix factorization to handle non-linearly separable clusters. Experimental results on synthetic datasets show that MISC can find different interesting clusterings from the sought independent subspaces, and it also outperforms other related and competitive approaches on real-world datasets.