 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers
Paper and Code
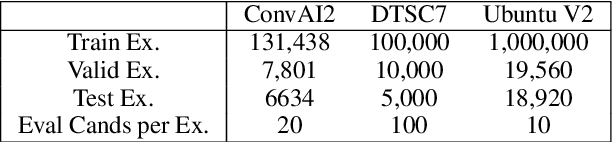
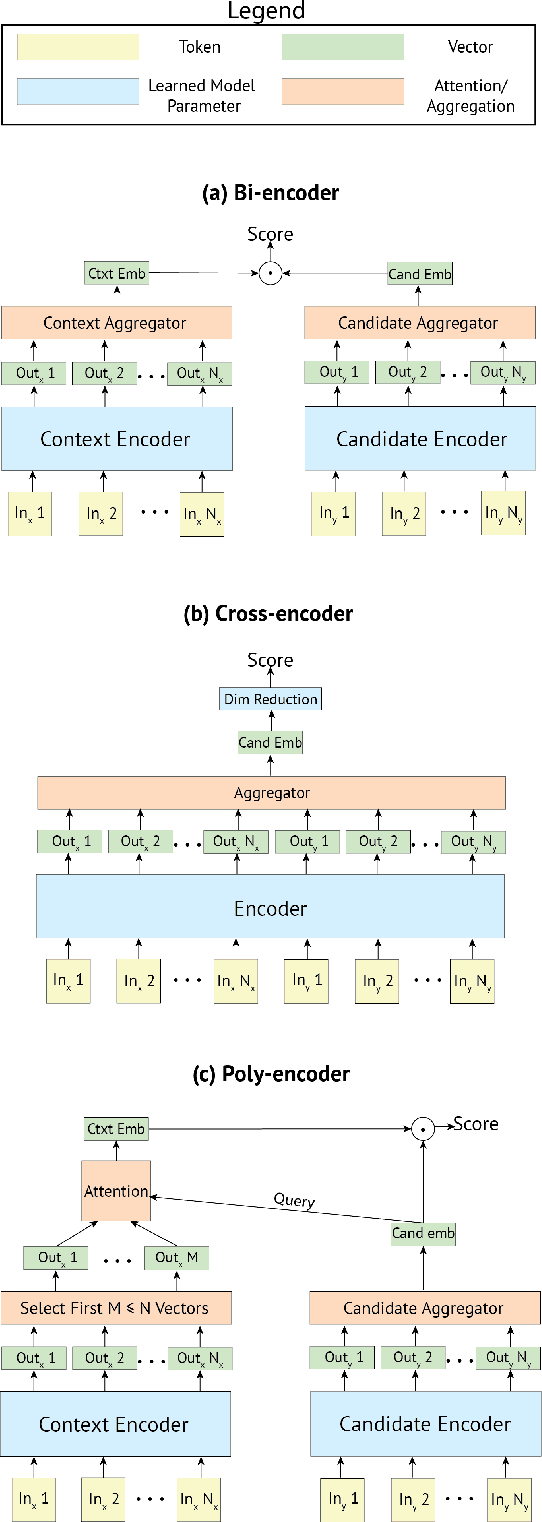

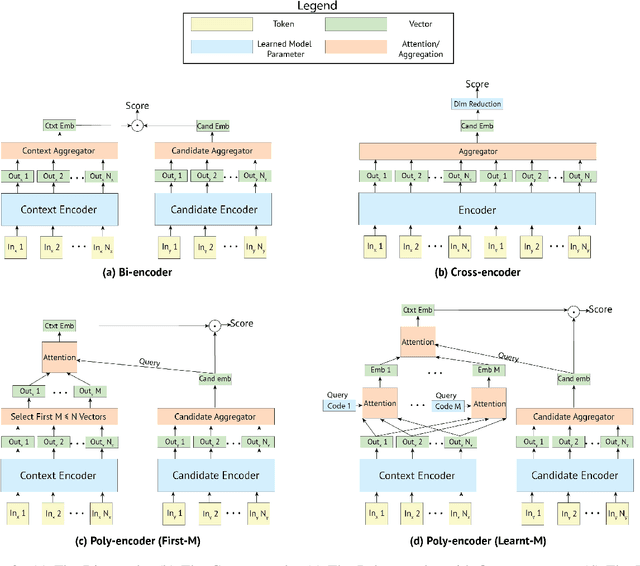
The use of deep pretrained bidirectional transformers has led to remarkable progress in learning multi-sentence representations for downstream language understanding tasks (Devlin et al., 2018). For tasks that make pairwise comparisons, e.g. matching a given context with a corresponding response, two approaches have permeated the literature. A Cross-encoder performs full self-attention over the pair; a Bi-encoder performs self-attention for each sequence separately, and the final representation is a function of the pair. While Cross-encoders nearly always outperform Bi-encoders on various tasks, both in our work and others' (Urbanek et al., 2019), they are orders of magnitude slower, which hampers their ability to perform real-time inference. In this work, we develop a new architecture, the Poly-encoder, that is designed to approach the performance of the Cross-encoder while maintaining reasonable computation time. Additionally, we explore two pretraining schemes with different datasets to determine how these affect the performance on our chosen dialogue tasks: ConvAI2 and DSTC7 Track 1. We show that our models achieve state-of-the-art results on both tasks; that the Poly-encoder is a suitable replacement for Bi-encoders and Cross-encoders; and that even better results can be obtained by pretraining on a large dialogue dataset.