 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study on Action Detection in the Wild
Paper and Code
Apr 29, 2019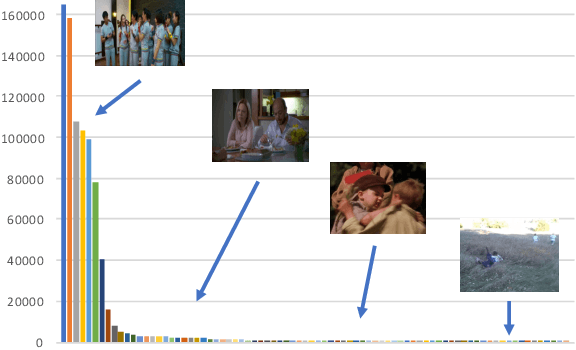
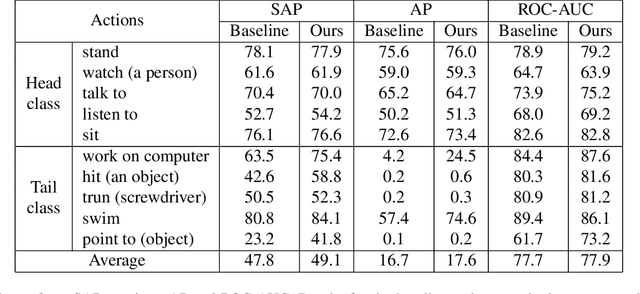
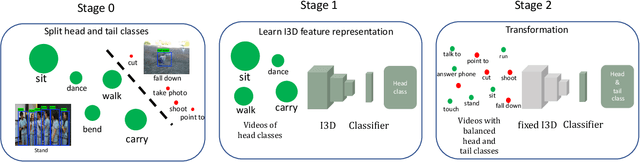
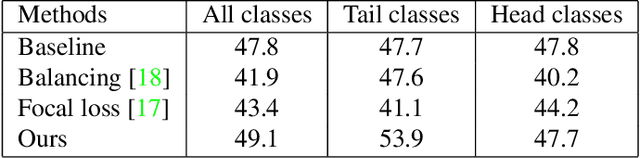
The recent introduction of the AVA dataset for action detection has caused a renewed interest to this problem. Several approaches have been recently proposed that improved the performance. However, all of them have ignored the main difficulty of the AVA dataset - its realistic distribution of training and test examples. This dataset was collected by exhaustive annotation of human action in uncurated videos. As a result, the most common categories, such as `stand' or `sit', contain tens of thousands of examples, where rare ones have only dozens. In this work we study the problem of action detection in highly-imbalanced dataset. Differently from previous work on handling long-tail category distributions, we begin by analyzing the imbalance in the test set. We demonstrate that the standard AP metric is not informative for the categories in the tail, and propose an alternative one - Sampled AP. Armed with this new measure, we study the problem of transferring representations from the data-rich head to the rare tail categories and propose a simple but effective approach.