 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiamese Attentional Keypoint Network for High Performance Visual Tracking
Paper and Code
Apr 23, 2019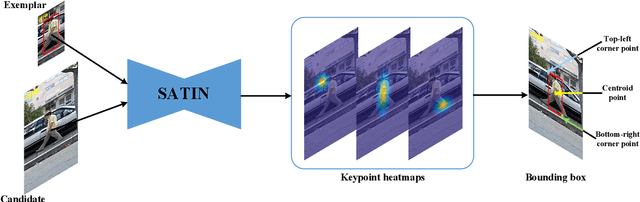
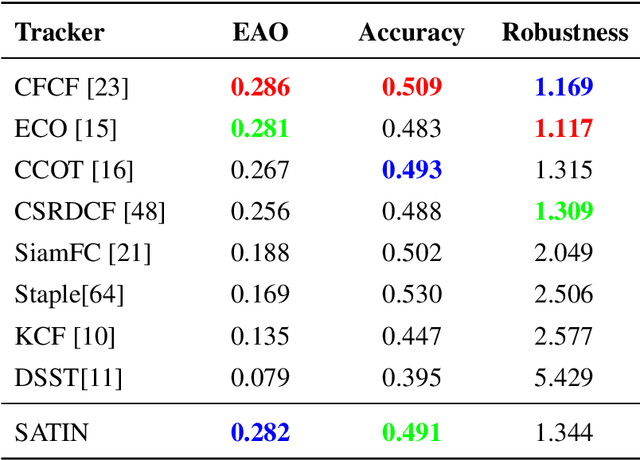
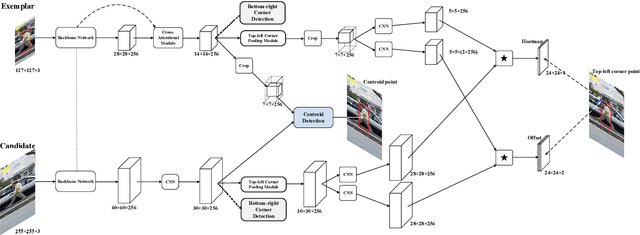
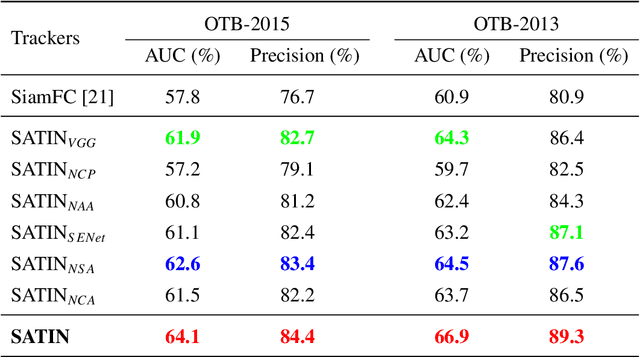
In this paper, we investigate impacts of three main aspects of visual tracking, i.e., the backbone network, the attentional mechanism and the detection component, and propose a Siamese Attentional Keypoint Network, dubbed SATIN, to achieve efficient tracking and accurate localization. Firstly, a new Siamese lightweight hourglass network is specifically designed for visual tracking. It takes advantage of the benefits of the repeated bottom-up and top-down inference to capture more global and local contextual information at multiple scales. Secondly, a novel cross-attentional module is utilized to leverage both channel-wise and spatial intermediate attentional information, which enhance both discriminative and localization capabilities of feature maps. Thirdly, a keypoints detection approach is invented to track any target object by detecting the top-left corner point, the centroid point and the bottom-right corner point of its bounding box. To the best of our knowledge, we are the first to propose this approach. Therefore, our SATIN tracker not only has a strong capability to learn more effective object representations, but also computational and memory storage efficiency, either during the training or testing stage. Without bells and whistles, experimental results demonstrate that our approach achieves state-of-the-art performance on several recent benchmark datasets, at speeds far exceeding the frame-rate requirement.