 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLATTE: Accelerating LiDAR Point Cloud Annotation via Sensor Fusion, One-Click Annotation, and Tracking
Paper and Code
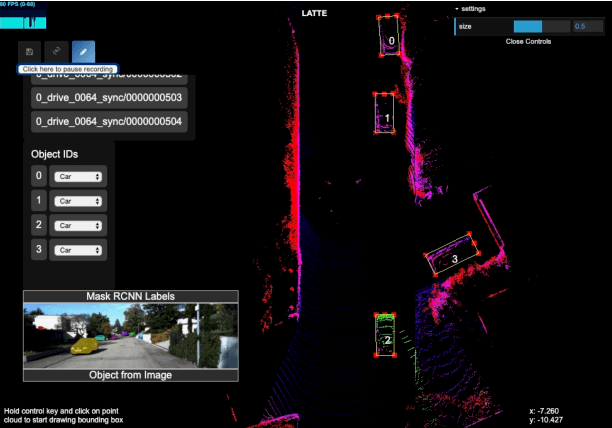
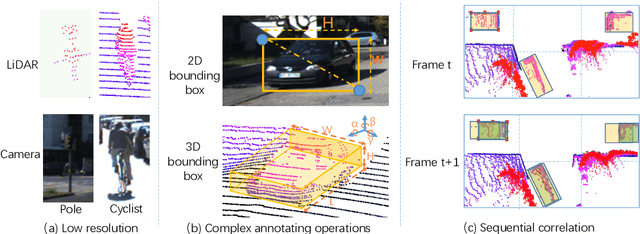
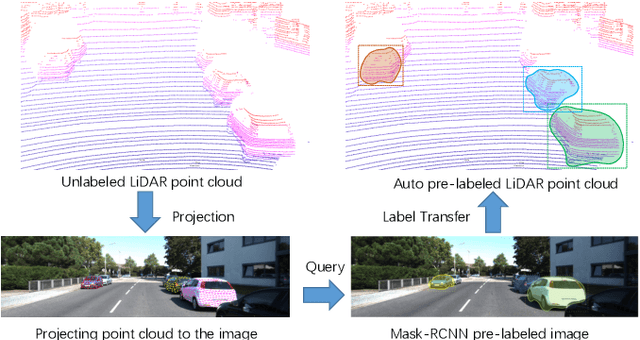
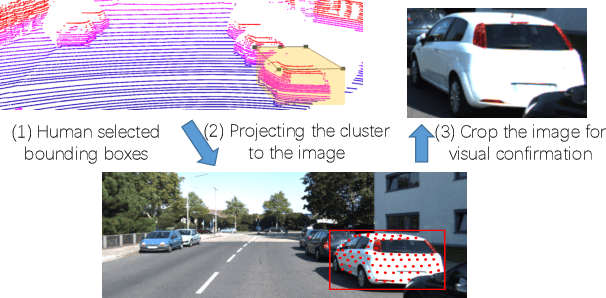
LiDAR (Light Detection And Ranging) is an essential and widely adopted sensor for autonomous vehicles, particularly for those vehicles operating at higher levels (L4-L5) of autonomy. Recent work has demonstrated the promise of deep-learning approaches for LiDAR-based detection. However, deep-learning algorithms are extremely data hungry, requiring large amounts of labeled point-cloud data for training and evaluation. Annotating LiDAR point cloud data is challenging due to the following issues: 1) A LiDAR point cloud is usually sparse and has low resolution, making it difficult for human annotators to recognize objects. 2) Compared to annotation on 2D images, the operation of drawing 3D bounding boxes or even point-wise labels on LiDAR point clouds is more complex and time-consuming. 3) LiDAR data are usually collected in sequences, so consecutive frames are highly correlated, leading to repeated annotations. To tackle these challenges, we propose LATTE, an open-sourced annotation tool for LiDAR point clouds. LATTE features the following innovations: 1) Sensor fusion: We utilize image-based detection algorithms to automatically pre-label a calibrated image, and transfer the labels to the point cloud. 2) One-click annotation: Instead of drawing 3D bounding boxes or point-wise labels, we simplify the annotation to just one click on the target object, and automatically generate the bounding box for the target. 3) Tracking: we integrate tracking into sequence annotation such that we can transfer labels from one frame to subsequent ones and therefore significantly reduce repeated labeling. Experiments show the proposed features accelerate the annotation speed by 6.2x and significantly improve label quality with 23.6% and 2.2% higher instance-level precision and recall, and 2.0% higher bounding box IoU. LATTE is open-sourced at https://github.com/bernwang/latte.