 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaseNet: Content-Adaptive Scale Interaction Networks for Scene Parsing
Paper and Code
Apr 17, 2019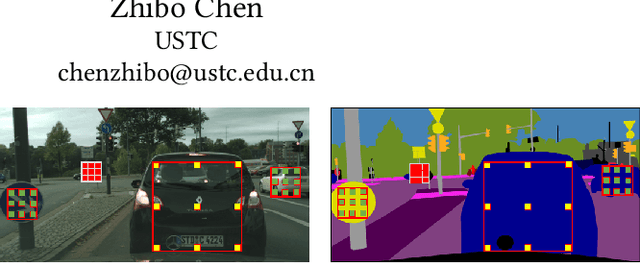
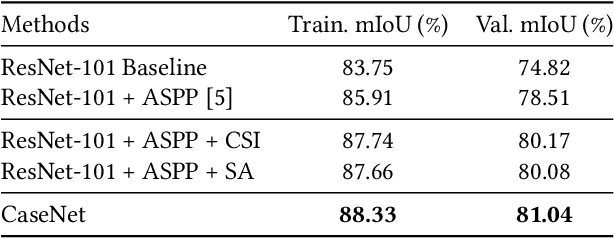
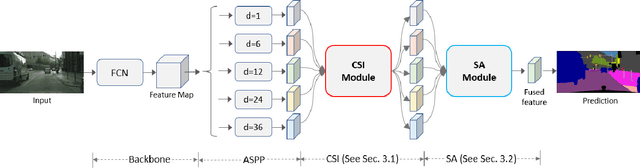

Objects in an image exhibit diverse scales. Adaptive receptive fields are expected to catch suitable range of context for accurate pixel level semantic prediction for handling objects of diverse sizes. Recently, atrous convolution with different dilation rates has been used to generate features of multi-scales through several branches and these features are fused for prediction. However, there is a lack of explicit interaction among the branches to adaptively make full use of the contexts. In this paper, we propose a Content-Adaptive Scale Interaction Network (CaseNet) to exploit the multi-scale features for scene parsing. We build the CaseNet based on the classic Atrous Spatial Pyramid Pooling (ASPP) module, followed by the proposed contextual scale interaction (CSI) module, and the scale adaptation (SA) module. Specifically, first, for each spatial position, we enable context interaction among different scales through scale-aware non-local operations across the scales, \ie, CSI module, which facilitates the generation of flexible mixed receptive fields, instead of a traditional flat one. Second, the scale adaptation module (SA) explicitly and softly selects the suitable scale for each spatial position and each channel. Ablation studies demonstrate the effectiveness of the proposed modules. We achieve state-of-the-art performance on three scene parsing benchmarks Cityscapes, ADE20K and LIP.