 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Learning in Statistical Classification: A Comprehensive Review of Defenses Against Attacks
Paper and Code
May 13, 2019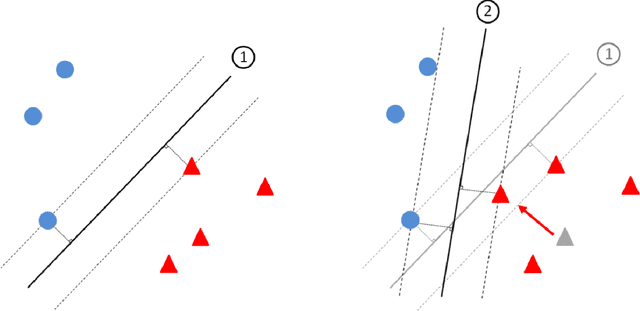
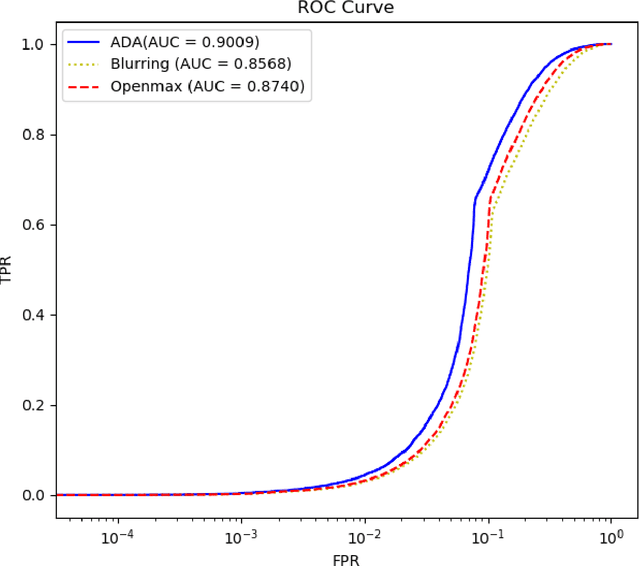
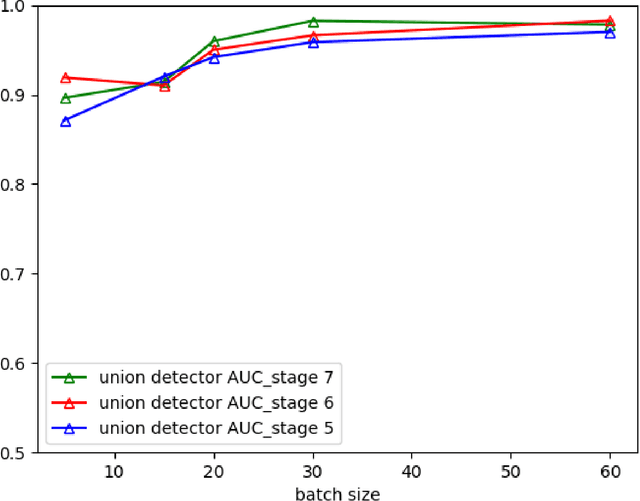
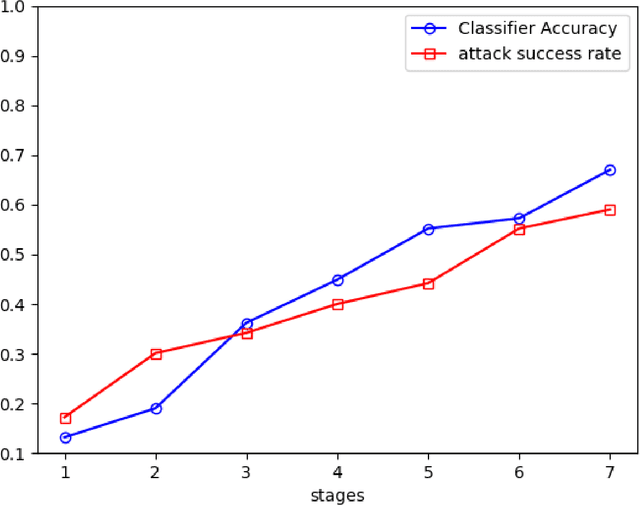
There is great potential for damage from adversarial learning (AL) attacks on machine-learning based systems. In this paper, we provide a contemporary survey of AL, focused particularly on defenses against attacks on statistical classifiers. After introducing relevant terminology and the goals and range of possible knowledge of both attackers and defenders, we survey recent work on test-time evasion (TTE), data poisoning (DP), and reverse engineering (RE) attacks and particularly defenses against same. In so doing, we distinguish robust classification from anomaly detection (AD), unsupervised from supervised, and statistical hypothesis-based defenses from ones that do not have an explicit null (no attack) hypothesis; we identify the hyperparameters a particular method requires, its computational complexity, as well as the performance measures on which it was evaluated and the obtained quality. We then dig deeper, providing novel insights that challenge conventional AL wisdom and that target unresolved issues, including: 1) robust classification versus AD as a defense strategy; 2) the belief that attack success increases with attack strength, which ignores susceptibility to AD; 3) small perturbations for test-time evasion attacks: a fallacy or a requirement?; 4) validity of the universal assumption that a TTE attacker knows the ground-truth class for the example to be attacked; 5) black, grey, or white box attacks as the standard for defense evaluation; 6) susceptibility of query-based RE to an AD defense. We also discuss attacks on the privacy of training data. We then present benchmark comparisons of several defenses against TTE, RE, and backdoor DP attacks on images. The paper concludes with a discussion of future work.