 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Hybrid Representations for Activity Forecasting with No-Regret Learning
Paper and Code
Apr 12, 2019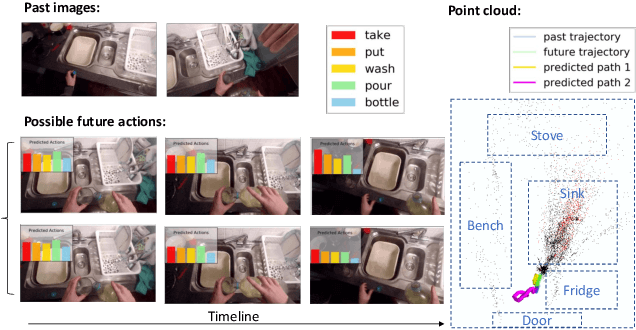

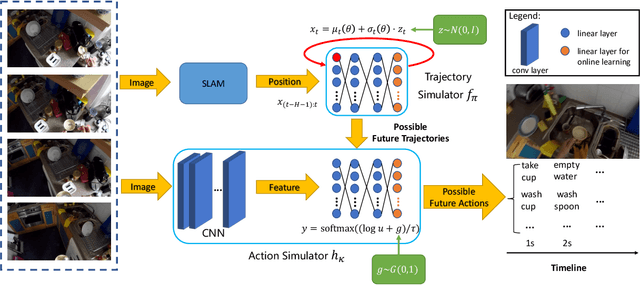
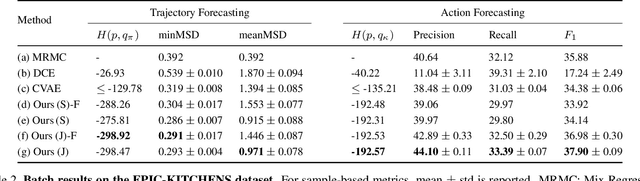
Automatically reasoning about future human behaviors is a difficult problem with significant practical applications to assistive systems. Part of this difficulty stems from learning systems' inability to represent all kinds of behaviors. Some behaviors, such as motion, are best described with continuous representations, whereas others, such as picking up a cup, are best described with discrete representations. Furthermore, human behavior is generally not fixed: people can change their habits and routines. This suggests these systems must be able to learn and adapt continuously. In this work, we develop an efficient deep generative model to jointly forecast a person's future discrete actions and continuous motions. On a large-scale egocentric dataset, EPIC-KITCHENS, we observe our method generates high-quality and diverse samples while exhibiting better generalization than related generative models. Finally, we propose a variant to continually learn our model from streaming data, observe its practical effectiveness, and theoretically justify its learning efficiency.