 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentive Action and Context Factorization
Paper and Code
Apr 10, 2019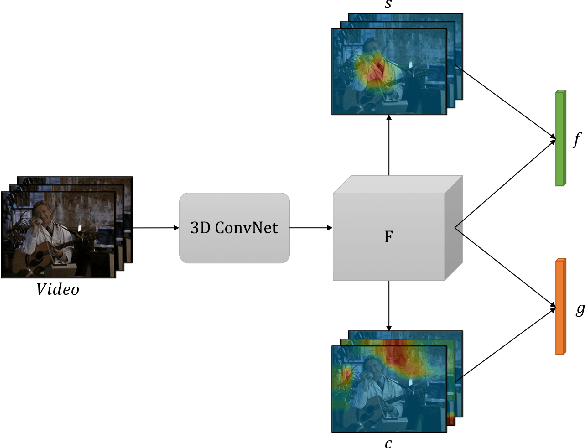
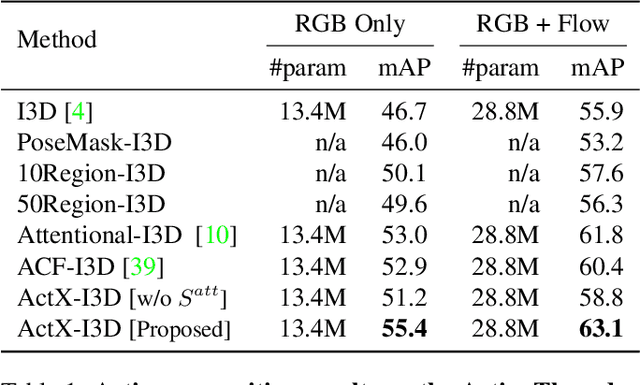
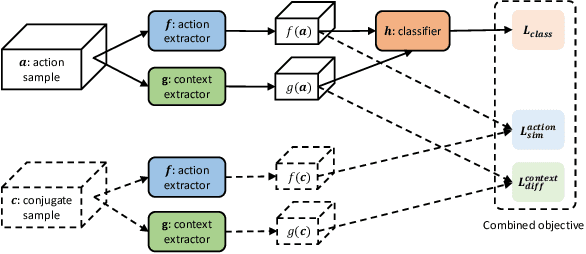
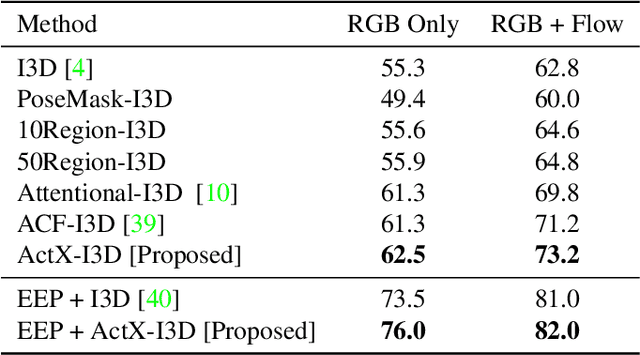
We propose a method for human action recognition, one that can localize the spatiotemporal regions that `define' the actions. This is a challenging task due to the subtlety of human actions in video and the co-occurrence of contextual elements. To address this challenge, we utilize conjugate samples of human actions, which are video clips that are contextually similar to human action samples but do not contain the action. We introduce a novel attentional mechanism that can spatially and temporally separate human actions from the co-occurring contextual factors. The separation of the action and context factors is weakly supervised, eliminating the need for laboriously detailed annotation of these two factors in training samples. Our method can be used to build human action classifiers with higher accuracy and better interpretability. Experiments on several human action recognition datasets demonstrate the quantitative and qualitative benefits of our approach.