 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Decoding Model For Spoken Language Understanding From Unaligned Data
Paper and Code
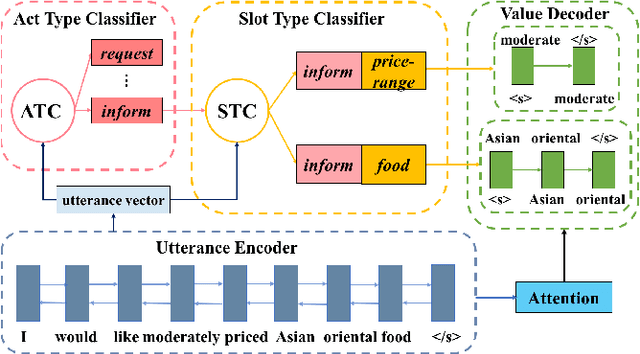

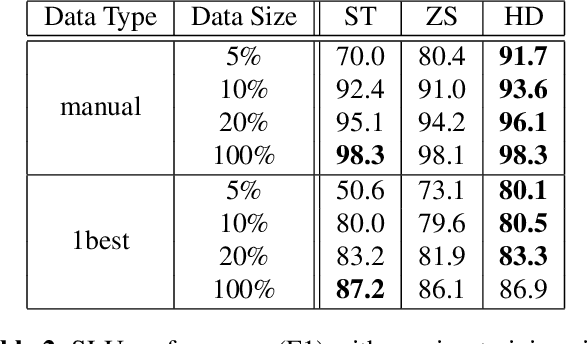
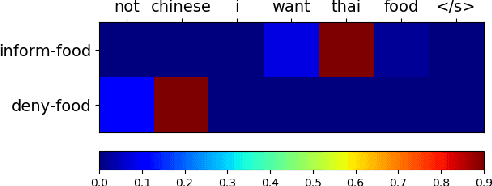
Spoken language understanding (SLU) systems can be trained on two types of labelled data: aligned or unaligned. Unaligned data do not require word by word annotation and is easier to be obtained. In the paper, we focus on spoken language understanding from unaligned data whose annotation is a set of act-slot-value triples. Previous works usually focus on improve slot-value pair prediction and estimate dialogue act types separately, which ignores the hierarchical structure of the act-slot-value triples. Here, we propose a novel hierarchical decoding model which dynamically parses act, slot and value in a structured way and employs pointer network to handle out-of-vocabulary (OOV) values. Experiments on DSTC2 dataset, a benchmark unaligned dataset, show that the proposed model not only outperforms previous state-of-the-art model, but also can be generalized effectively and efficiently to unseen act-slot type pairs and OOV values.