 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dilated Inception Network for Visual Saliency Prediction
Paper and Code
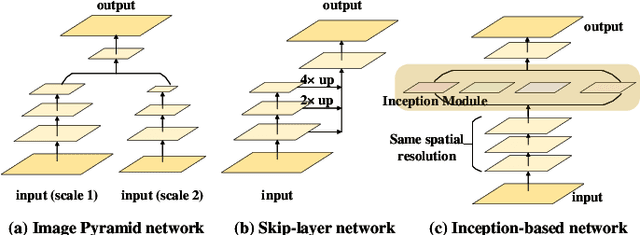
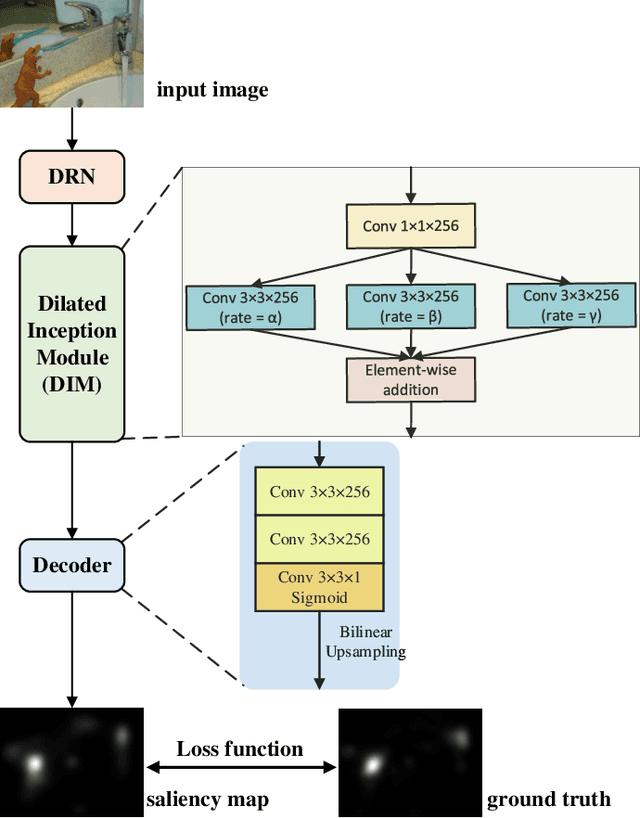
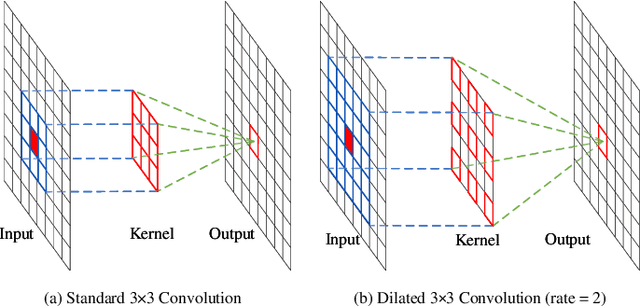
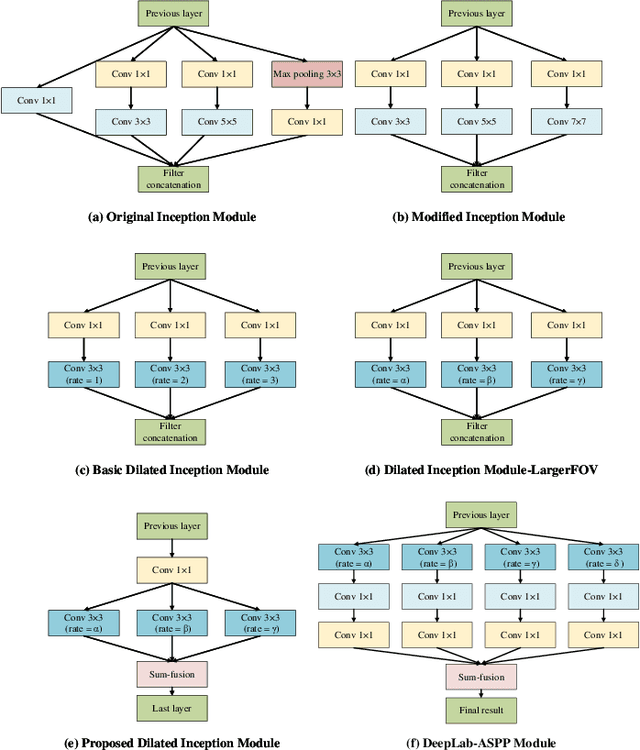
Recently, with the advent of deep convolutional neural networks (DCNN), the improvements in visual saliency prediction research are impressive. One possible direction to approach the next improvement is to fully characterize the multi-scale saliency-influential factors with a computationally-friendly module in DCNN architectures. In this work, we proposed an end-to-end dilated inception network (DINet) for visual saliency prediction. It captures multi-scale contextual features effectively with very limited extra parameters. Instead of utilizing parallel standard convolutions with different kernel sizes as the existing inception module, our proposed dilated inception module (DIM) uses parallel dilated convolutions with different dilation rates which can significantly reduce the computation load while enriching the diversity of receptive fields in feature maps. Moreover, the performance of our saliency model is further improved by using a set of linear normalization-based probability distribution distance metrics as loss functions. As such, we can formulate saliency prediction as a probability distribution prediction task for global saliency inference instead of a typical pixel-wise regression problem. Experimental results on several challenging saliency benchmark datasets demonstrate that our DINet with proposed loss functions can achieve state-of-the-art performance with shorter inference time.