 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Preference Actor Critic
Paper and Code
Apr 05, 2019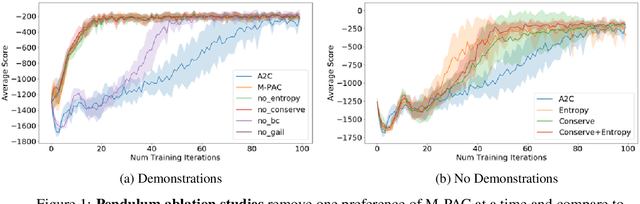
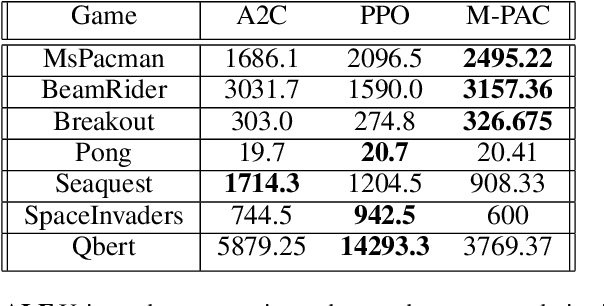
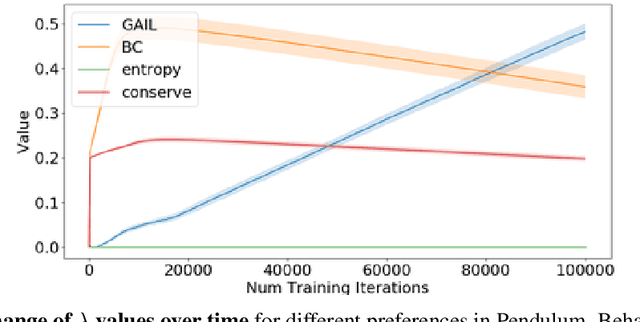
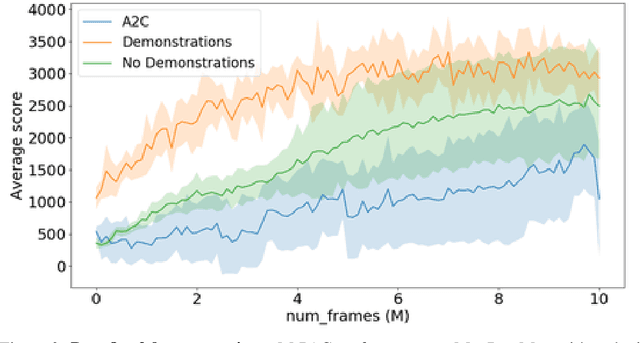
Policy gradient algorithms typically combine discounted future rewards with an estimated value function, to compute the direction and magnitude of parameter updates. However, for most Reinforcement Learning tasks, humans can provide additional insight to constrain the policy learning. We introduce a general method to incorporate multiple different feedback channels into a single policy gradient loss. In our formulation, the Multi-Preference Actor Critic (M-PAC), these different types of feedback are implemented as constraints on the policy. We use a Lagrangian relaxation to satisfy these constraints using gradient descent while learning a policy that maximizes rewards. Experiments in Atari and Pendulum verify that constraints are being respected and can accelerate the learning process.