 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting segmentation with weak supervision from image-to-image translation
Paper and Code
Apr 04, 2019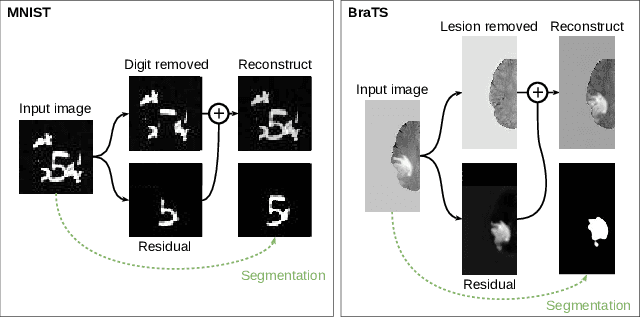

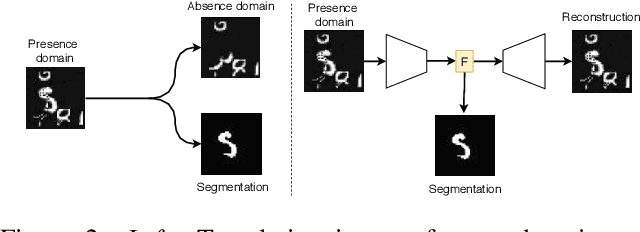
In many cases, especially with medical images, it is prohibitively challenging to produce a sufficiently large training sample of pixel-level annotations to train deep neural networks for semantic image segmentation. On the other hand, some information is often known about the contents of images. We leverage information on whether an image presents the segmentation target or whether it is absent from the image to improve segmentation performance by augmenting the amount of data usable for model training. Specifically, we propose a semi-supervised framework that employs image-to-image translation between weak labels (e.g., presence vs. absence of cancer), in addition to fully supervised segmentation on some examples. We conjecture that this translation objective is well aligned with the segmentation objective as both require the same disentangling of image variations. Building on prior image-to-image translation work, we re-use the encoder and decoders for translating in either direction between two domains, employing a strategy of selectively decoding domain-specific variations. For presence vs. absence domains, the encoder produces variations that are common to both and those unique to the presence domain. Furthermore, we successfully re-use one of the decoders used in translation for segmentation. We validate the proposed method on synthetic tasks of varying difficulty as well as on the real task of brain tumor segmentation in magnetic resonance images, where we show significant improvements over standard semi-supervised training with autoencoding.