 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attacks against Deep Saliency Models
Paper and Code
Apr 02, 2019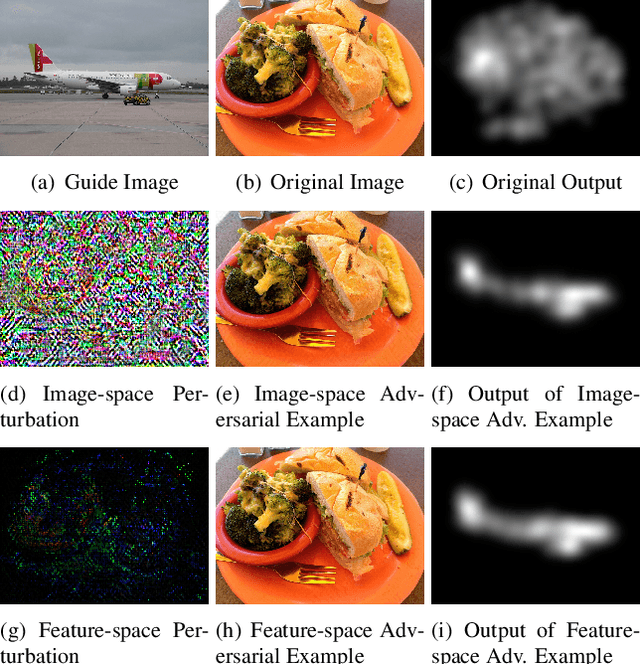
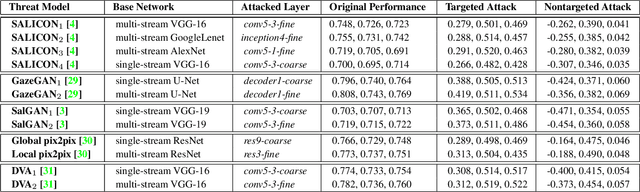
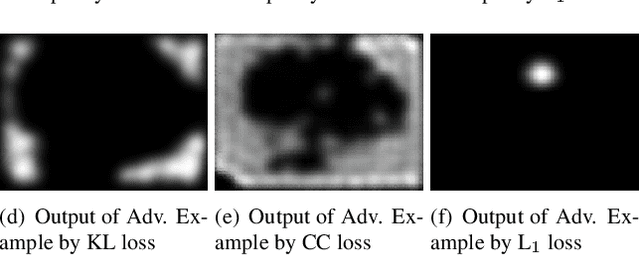
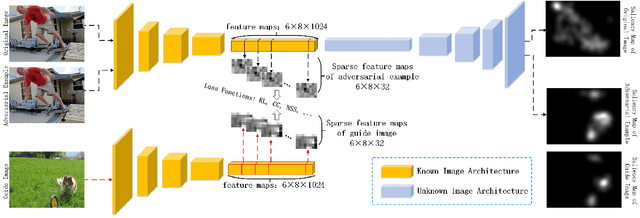
Currently, a plethora of saliency models based on deep neural networks have led great breakthroughs in many complex high-level vision tasks (e.g. scene description, object detection). The robustness of these models, however, has not yet been studied. In this paper, we propose a sparse feature-space adversarial attack method against deep saliency models for the first time. The proposed attack only requires a part of the model information, and is able to generate a sparser and more insidious adversarial perturbation, compared to traditional image-space attacks. These adversarial perturbations are so subtle that a human observer cannot notice their presences, but the model outputs will be revolutionized. This phenomenon raises security threats to deep saliency models in practical applications. We also explore some intriguing properties of the feature-space attack, e.g. 1) the hidden layers with bigger receptive fields generate sparser perturbations, 2) the deeper hidden layers achieve higher attack success rates, and 3) different loss functions and different attacked layers will result in diverse perturbations. Experiments indicate that the proposed method is able to successfully attack different model architectures across various image scenes.