 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics-Guided Neural Networks for Efficient Skeleton-Based Human Action Recognition
Paper and Code
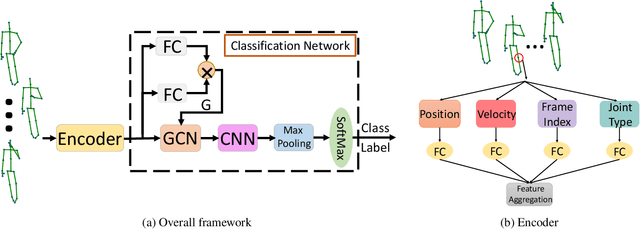

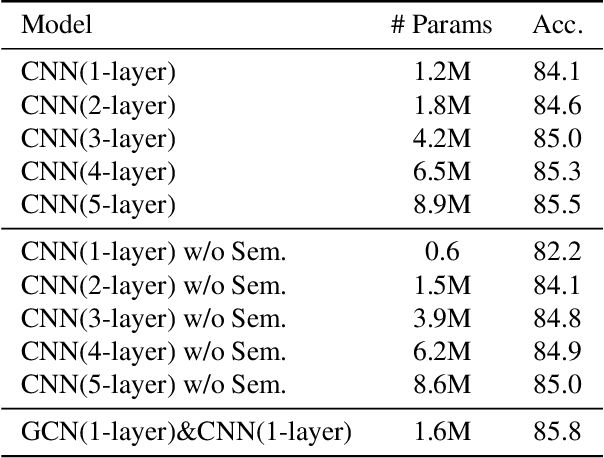
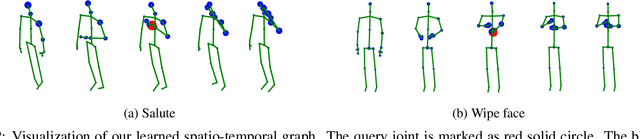
Skeleton-based human action recognition has attracted a lot of interests. Recently, there is a trend of using deep feedforward neural networks to model the skeleton sequence which takes the 2D spatio-temporal map derived from the 3D coordinates of joints as input. Some semantics of the joints (frame index and joint type) are implicitly captured and exploited by large receptive fields of deep convolutions at the cost of high complexity. In this paper, we propose a simple yet effective semantics-guided neural network (SGN) for skeleton-based action recognition. We explicitly introduce the high level semantics of joints as part of the network input to enhance the feature representation capability. The model exploits the global and local information through two semantics-aware graph convolutional layers followed by a convolutional layer. We first leverage the semantics and dynamics (coordinate and velocity) of joints to learn a content adaptive graph for capturing the global spatio-temporal correlations of joints. Then a convolutional layer is used to further enhance the representation power of the features. With an order of magnitude smaller model size and higher speed than some previous works, SGN achieves the state-of-the-art performance on the NTU, SYSU, and N-UCLA datasets. Experimental results demonstrate the effectiveness of explicitly exploiting semantic information in reducing model complexity and improving the recognition accuracy.