 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe-Ranking Words to Improve Interpretability of Automatically Generated Topics
Paper and Code


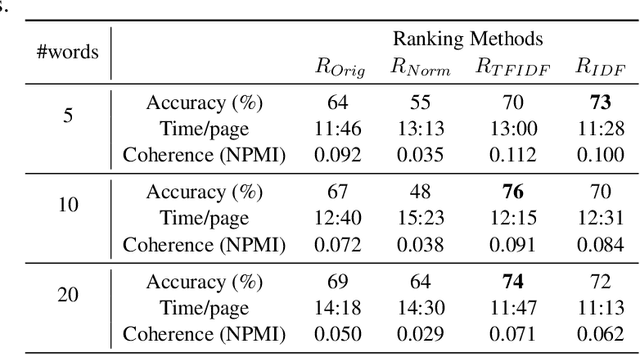
Topics models, such as LDA, are widely used in Natural Language Processing. Making their output interpretable is an important area of research with applications to areas such as the enhancement of exploratory search interfaces and the development of interpretable machine learning models. Conventionally, topics are represented by their n most probable words, however, these representations are often difficult for humans to interpret. This paper explores the re-ranking of topic words to generate more interpretable topic representations. A range of approaches are compared and evaluated in two experiments. The first uses crowdworkers to associate topics represented by different word rankings with related documents. The second experiment is an automatic approach based on a document retrieval task applied on multiple domains. Results in both experiments demonstrate that re-ranking words improves topic interpretability and that the most effective re-ranking schemes were those which combine information about the importance of words both within topics and their relative frequency in the entire corpus. In addition, close correlation between the results of the two evaluation approaches suggests that the automatic method proposed here could be used to evaluate re-ranking methods without the need for human judgements.