 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Probabilistic Prediction of Interactive Behavior via an Interpretable Model
Paper and Code
Mar 22, 2019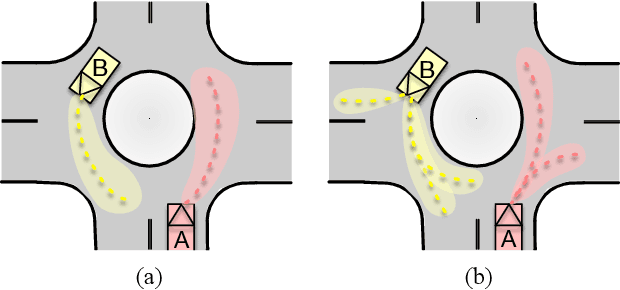
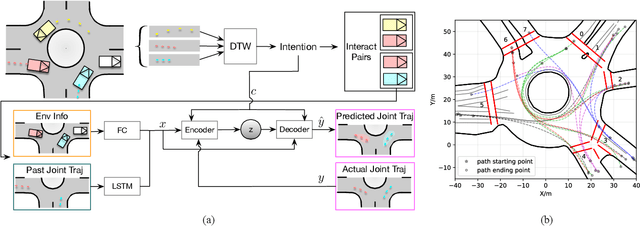
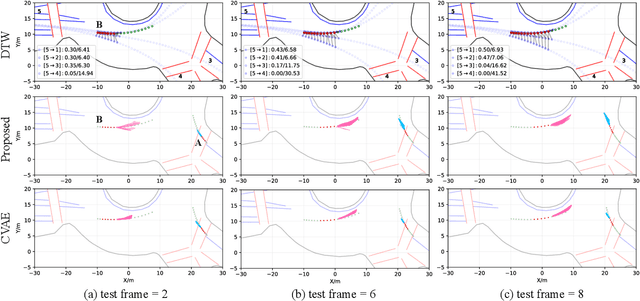
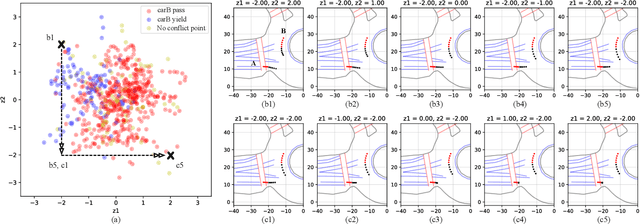
For autonomous agents to successfully operate in real world, the ability to anticipate future motions of surrounding entities in the scene can greatly enhance their safety levels since potentially dangerous situations could be avoided in advance. While impressive results have been shown on predicting each agent's behavior independently, we argue that it is not valid to consider road entities individually since transitions of vehicle states are highly coupled. Moreover, as the predicted horizon becomes longer, modeling prediction uncertainties and multi-modal distributions over future sequences will turn into a more challenging task. In this paper, we address this challenge by presenting a multi-modal probabilistic prediction approach. The proposed method is based on a generative model and is capable of jointly predicting sequential motions of each pair of interacting agents. Most importantly, our model is interpretable, which can explain the underneath logic as well as obtain more reliability to use in real applications. A complicate real-world roundabout scenario is utilized to implement and examine the proposed method.