Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Deep Set Learning and the Choice of Aggregations
Paper and Code
Mar 18, 2019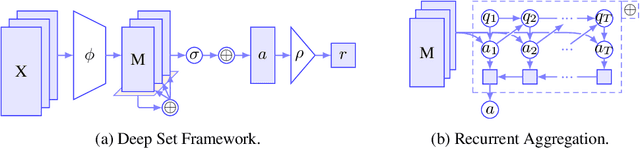
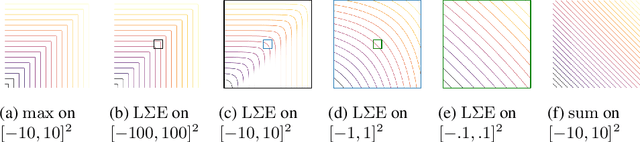
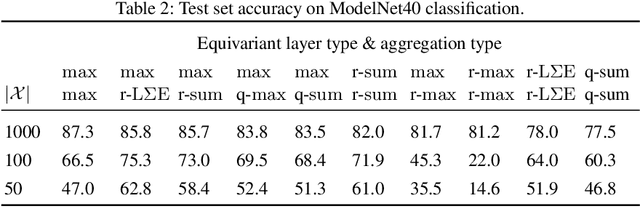
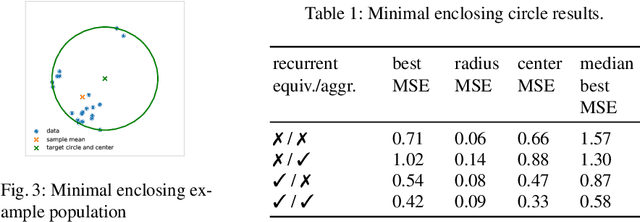
Recently, it has been shown that many functions on sets can be represented by sum decompositions. These decompositons easily lend themselves to neural approximations, extending the applicability of neural nets to set-valued inputs---Deep Set learning. This work investigates a core component of Deep Set architecture: aggregation functions. We suggest and examine alternatives to commonly used aggregation functions, including learnable recurrent aggregation functions. Empirically, we show that the Deep Set networks are highly sensitive to the choice of aggregation functions: beyond improved performance, we find that learnable aggregations lower hyper-parameter sensitivity and generalize better to out-of-distribution input size.
View paper on