 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy Distillation and Value Matching in Multiagent Reinforcement Learning
Paper and Code
Mar 15, 2019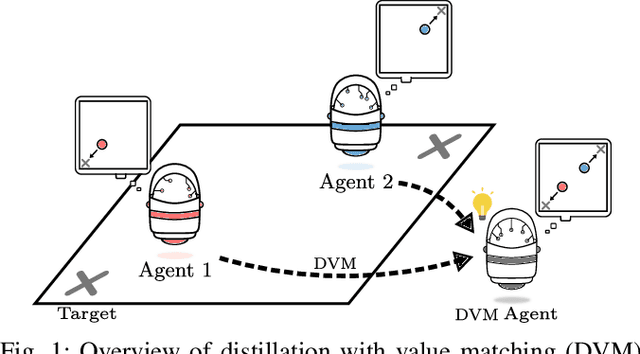
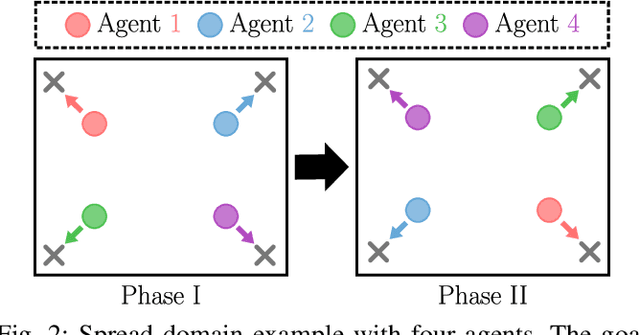
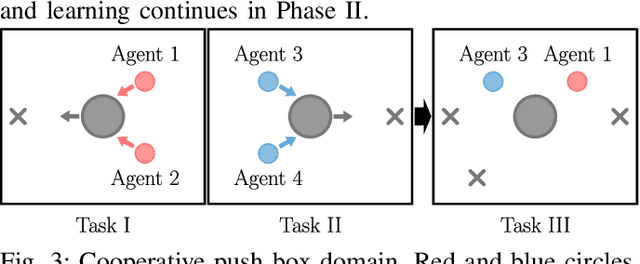
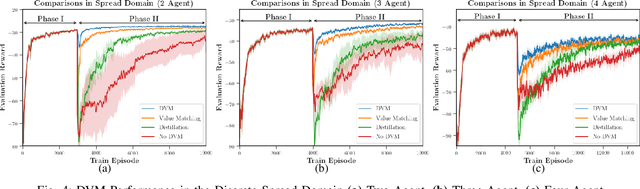
Multiagent reinforcement learning algorithms (MARL) have been demonstrated on complex tasks that require the coordination of a team of multiple agents to complete. Existing works have focused on sharing information between agents via centralized critics to stabilize learning or through communication to increase performance, but do not generally look at how information can be shared between agents to address the curse of dimensionality in MARL. We posit that a multiagent problem can be decomposed into a multi-task problem where each agent explores a subset of the state space instead of exploring the entire state space. This paper introduces a multiagent actor-critic algorithm and method for combining knowledge from homogeneous agents through distillation and value-matching that outperforms policy distillation alone and allows further learning in both discrete and continuous action spaces.