 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Adaptation for Efficient Semantic Segmentation
Paper and Code
Mar 12, 2019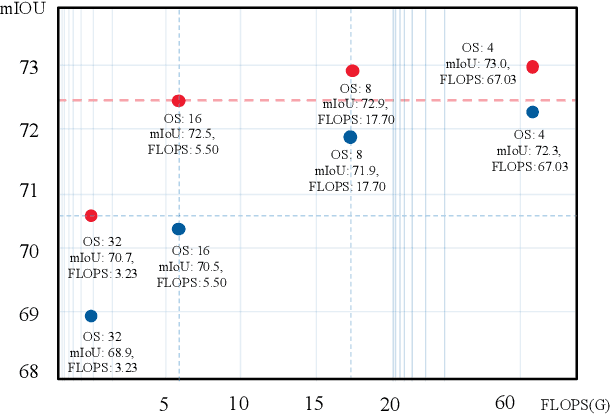
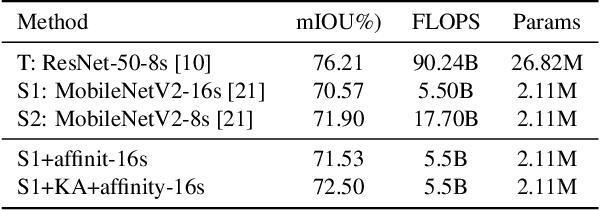
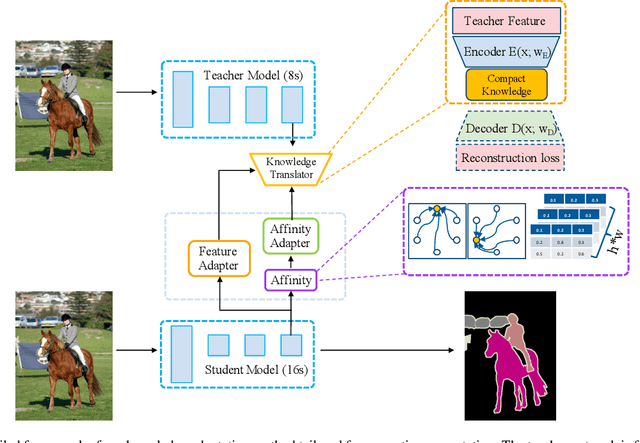
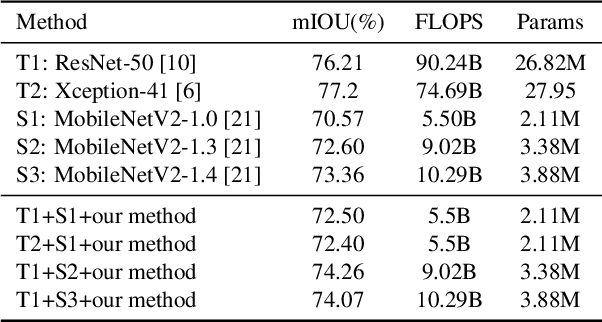
Both accuracy and efficiency are of significant importance to the task of semantic segmentation. Existing deep FCNs suffer from heavy computations due to a series of high-resolution feature maps for preserving the detailed knowledge in dense estimation. Although reducing the feature map resolution (i.e., applying a large overall stride) via subsampling operations (e.g., pooling and convolution striding) can instantly increase the efficiency, it dramatically decreases the estimation accuracy. To tackle this dilemma, we propose a knowledge distillation method tailored for semantic segmentation to improve the performance of the compact FCNs with large overall stride. To handle the inconsistency between the features of the student and teacher network, we optimize the feature similarity in a transferred latent domain formulated by utilizing a pre-trained autoencoder. Moreover, an affinity distillation module is proposed to capture the long-range dependency by calculating the non-local interactions across the whole image. To validate the effectiveness of our proposed method, extensive experiments have been conducted on three popular benchmarks: Pascal VOC, Cityscapes and Pascal Context. Built upon a highly competitive baseline, our proposed method can improve the performance of a student network by 2.5\% (mIOU boosts from 70.2 to 72.7 on the cityscapes test set) and can train a better compact model with only 8\% float operations (FLOPS) of a model that achieves comparable performances.