 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Ontology Learning from Domain-Specific Short Unstructured Text Data
Paper and Code
Mar 07, 2019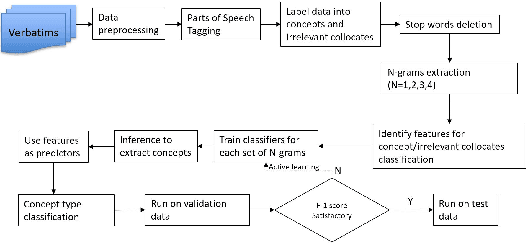
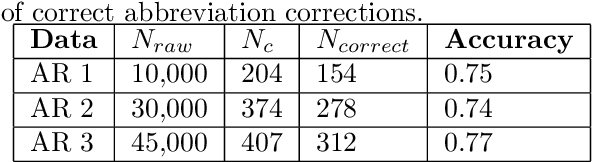
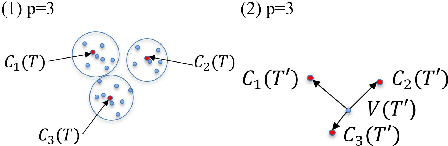
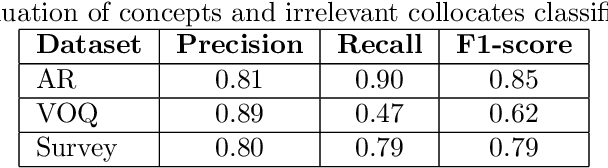
Ontology learning is a critical task in industry, dealing with identifying and extracting concepts captured in text data such that these concepts can be used in different tasks, e.g. information retrieval. Ontology learning is non-trivial due to several reasons with limited amount of prior research work that automatically learns a domain specific ontology from data. In our work, we propose a two-stage classification system to automatically learn an ontology from unstructured text data. We first collect candidate concepts, which are classified into concepts and irrelevant collocates by our first classifier. The concepts from the first classifier are further classified by the second classifier into different concept types. The proposed system is deployed as a prototype at a company and its performance is validated by using complaint and repair verbatim data collected in automotive industry from different data sources.