 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConcurrent Meta Reinforcement Learning
Paper and Code
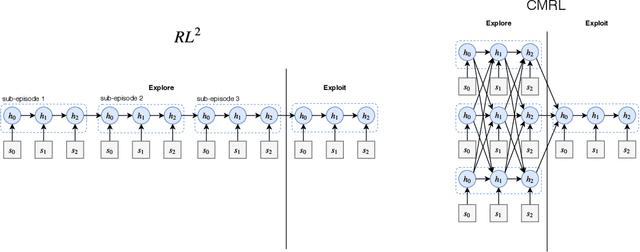
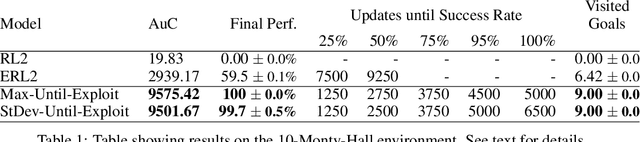
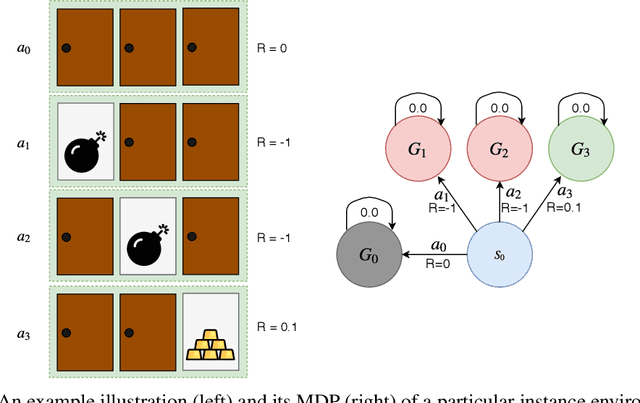

State-of-the-art meta reinforcement learning algorithms typically assume the setting of a single agent interacting with its environment in a sequential manner. A negative side-effect of this sequential execution paradigm is that, as the environment becomes more and more challenging, and thus requiring more interaction episodes for the meta-learner, it needs the agent to reason over longer and longer time-scales. To combat the difficulty of long time-scale credit assignment, we propose an alternative parallel framework, which we name "Concurrent Meta-Reinforcement Learning" (CMRL), that transforms the temporal credit assignment problem into a multi-agent reinforcement learning one. In this multi-agent setting, a set of parallel agents are executed in the same environment and each of these "rollout" agents are given the means to communicate with each other. The goal of the communication is to coordinate, in a collaborative manner, the most efficient exploration of the shared task the agents are currently assigned. This coordination therefore represents the meta-learning aspect of the framework, as each agent can be assigned or assign itself a particular section of the current task's state space. This framework is in contrast to standard RL methods that assume that each parallel rollout occurs independently, which can potentially waste computation if many of the rollouts end up sampling the same part of the state space. Furthermore, the parallel setting enables us to define several reward sharing functions and auxiliary losses that are non-trivial to apply in the sequential setting. We demonstrate the effectiveness of our proposed CMRL at improving over sequential methods in a variety of challenging tasks.