 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Episodic Deep Deterministic Policy Gradient: Towards Continuous Control in Computationally Complex Environments
Paper and Code
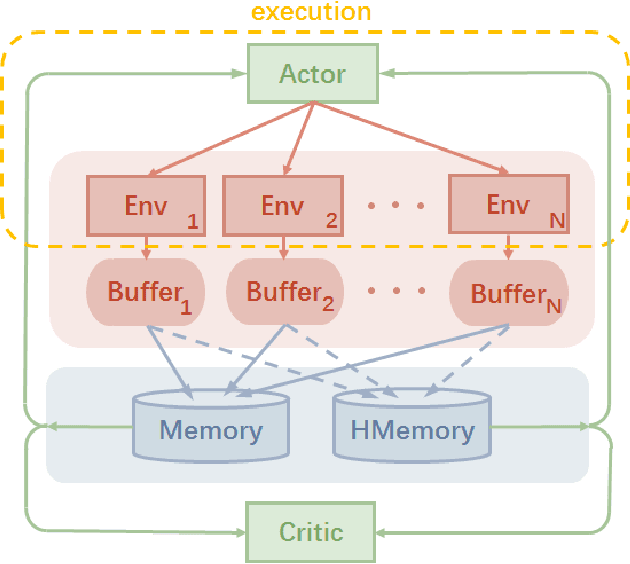
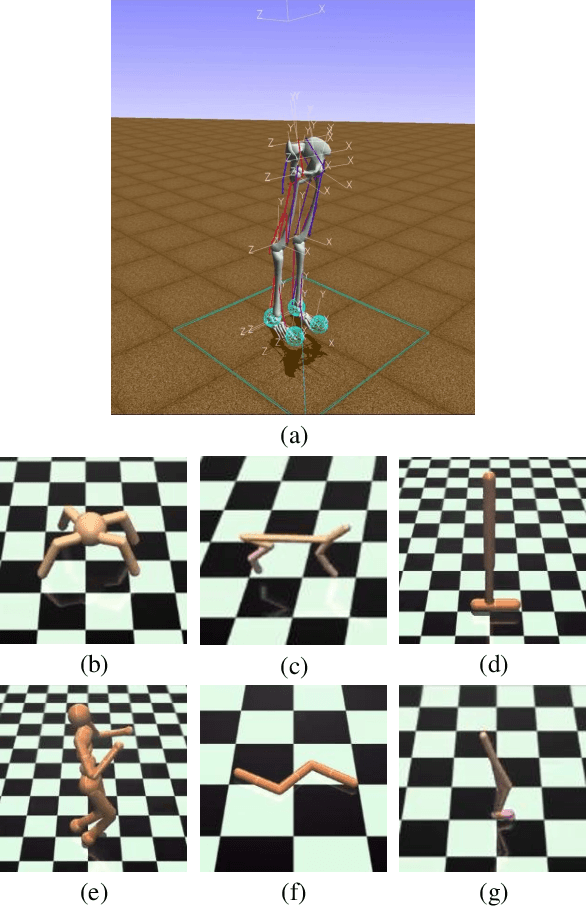
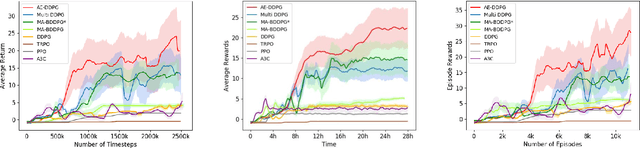
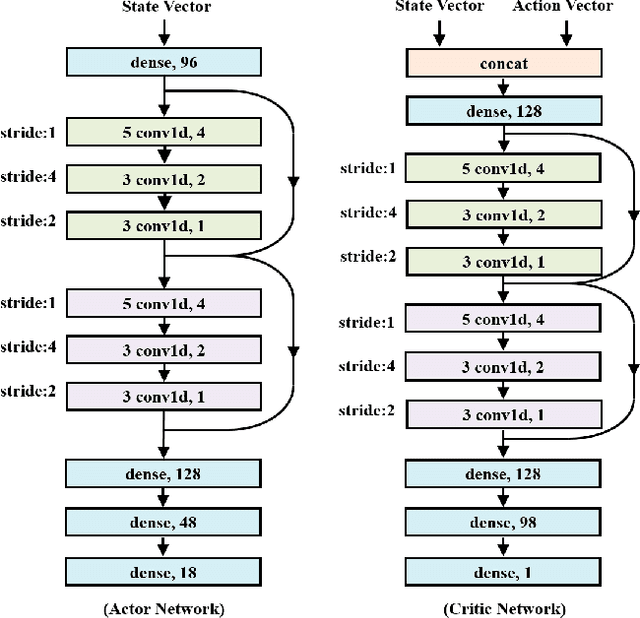
Deep Deterministic Policy Gradient (DDPG) has been proved to be a successful reinforcement learning (RL) algorithm for continuous control tasks. However, DDPG still suffers from data insufficiency and training inefficiency, especially in computationally complex environments. In this paper, we propose Asynchronous Episodic DDPG (AE-DDPG), as an expansion of DDPG, which can achieve more effective learning with less training time required. First, we design a modified scheme for data collection in an asynchronous fashion. Generally, for asynchronous RL algorithms, sample efficiency or/and training stability diminish as the degree of parallelism increases. We consider this problem from the perspectives of both data generation and data utilization. In detail, we re-design experience replay by introducing the idea of episodic control so that the agent can latch on good trajectories rapidly. In addition, we also inject a new type of noise in action space to enrich the exploration behaviors. Experiments demonstrate that our AE-DDPG achieves higher rewards and requires less time consuming than most popular RL algorithms in Learning to Run task which has a computationally complex environment. Not limited to the control tasks in computationally complex environments, AE-DDPG also achieves higher rewards and 2- to 4-fold improvement in sample efficiency on average compared to other variants of DDPG in MuJoCo environments. Furthermore, we verify the effectiveness of each proposed technique component through abundant ablation study.