 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Exploration in Markov Decision Processes
Paper and Code
Feb 28, 2019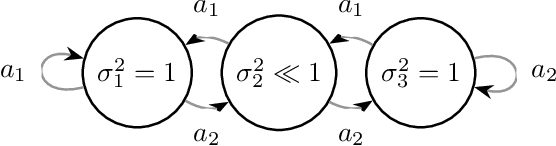
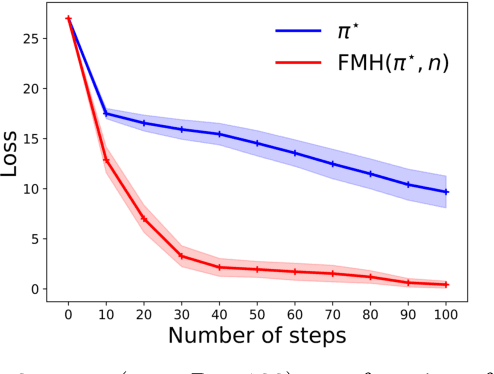
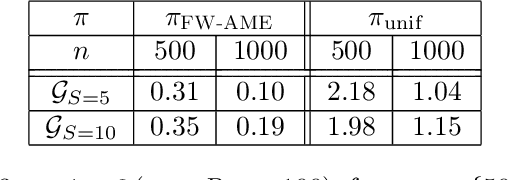
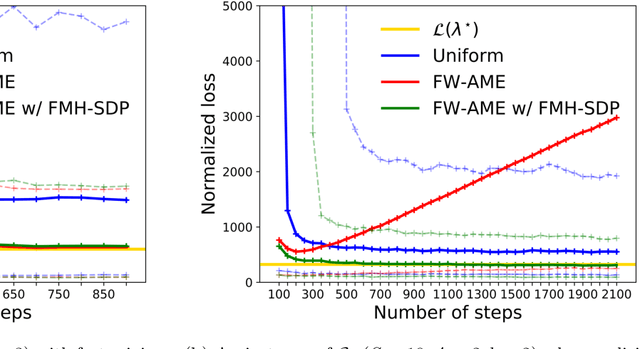
We introduce the active exploration problem in Markov decision processes (MDPs). Each state of the MDP is characterized by a random value and the learner should gather samples to estimate the mean value of each state as accurately as possible. Similarly to active exploration in multi-armed bandit (MAB), states may have different levels of noise, so that the higher the noise, the more samples are needed. As the noise level is initially unknown, we need to trade off the exploration of the environment to estimate the noise and the exploitation of these estimates to compute a policy maximizing the accuracy of the mean predictions. We introduce a novel learning algorithm to solve this problem showing that active exploration in MDPs may be significantly more difficult than in MAB. We also derive a heuristic procedure to mitigate the negative effect of slowly mixing policies. Finally, we validate our findings on simple numerical simulations.