 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Photometric Loss for Self-Supervised Ego-Motion Estimation
Paper and Code
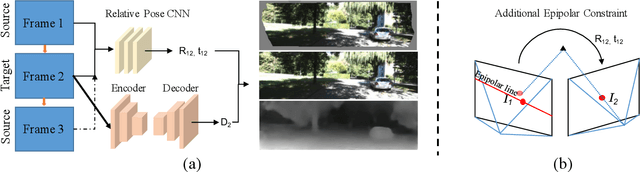


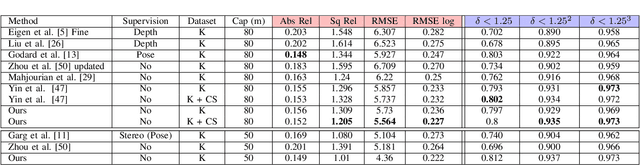
Accurate relative pose is one of the key components in visual odometry (VO) and simultaneous localization and mapping (SLAM). Recently, the self-supervised learning framework that jointly optimizes the relative pose and target image depth has attracted the attention of the community. Previous works rely on the photometric error generated from depths and poses between adjacent frames, which contains large systematic error under realistic scenes due to reflective surfaces and occlusions. In this paper, we bridge the gap between geometric loss and photometric loss by introducing the matching loss constrained by epipolar geometry in a self-supervised framework. Evaluated on the KITTI dataset, our method outperforms the state-of-the-art unsupervised ego-motion estimation methods by a large margin. The code and data are available at https://github.com/hlzz/DeepMatchVO.