 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Reinforcement Learning under Partial Observability in Software-Defined Networking
Paper and Code
Feb 25, 2019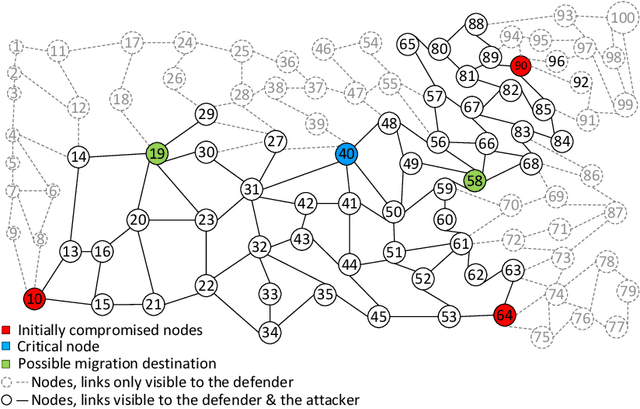

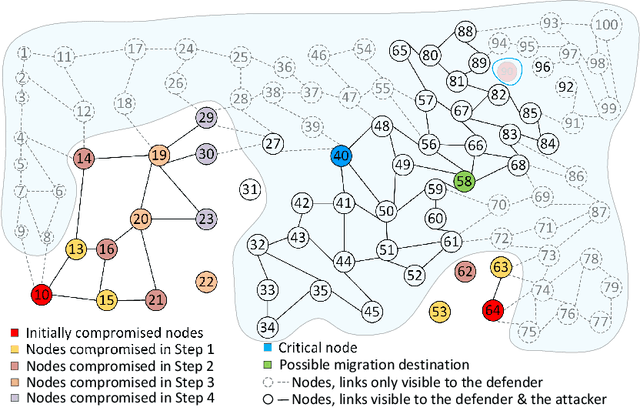
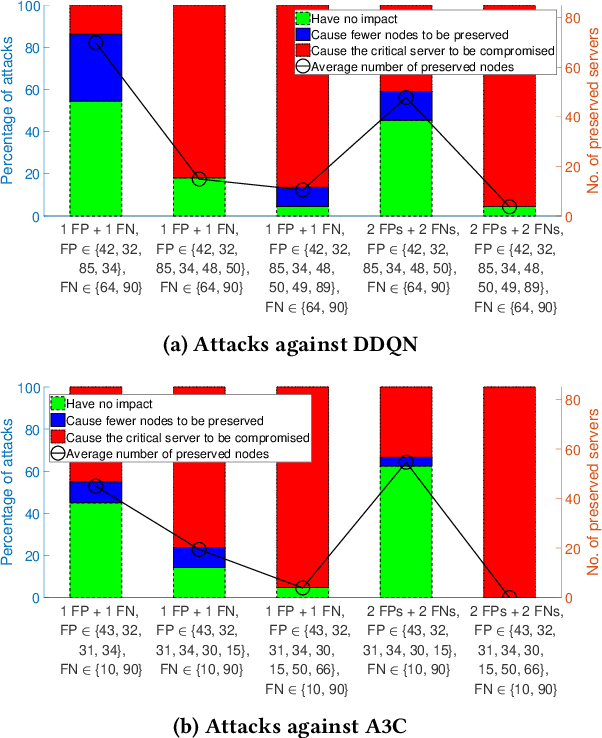
Recent studies have demonstrated that reinforcement learning (RL) agents are susceptible to adversarial manipulation, similar to vulnerabilities previously demonstrated in the supervised setting. Accordingly focus has remained with computer vision, and full observability. This paper focuses on reinforcement learning in the context of autonomous defence in Software-Defined Networking (SDN). We demonstrate that causative attacks---attacks that target the training process---can poison RL agents even if the attacker only has partial observability of the environment. In addition, we propose an inversion defence method that aims to apply the opposite perturbation to that which an attacker might use to generate their adversarial samples. Our experimental results illustrate that the countermeasure can effectively reduce the impact of the causative attack, while not significantly affecting the training process in non-attack scenarios.