 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegularizing Black-box Models for Improved Interpretability
Paper and Code
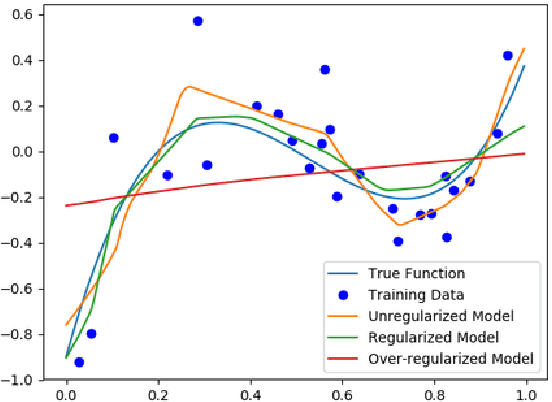
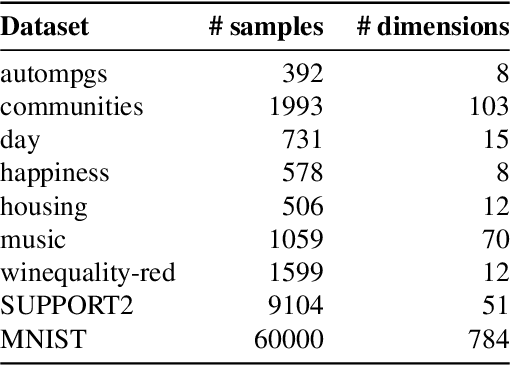
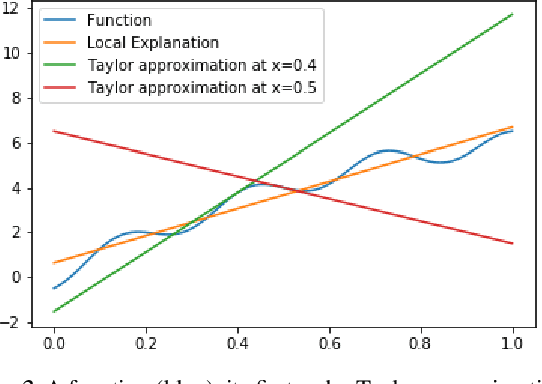
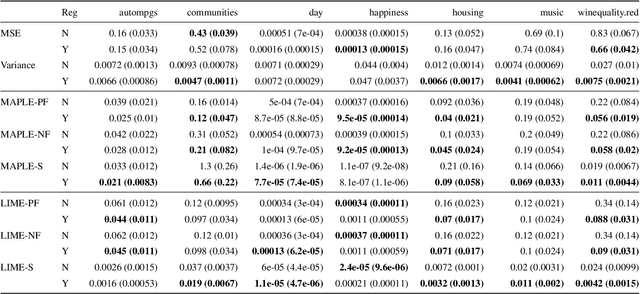
Most work on interpretability in machine learning has focused on designing either inherently interpretable models, that typically trade-off interpretability for accuracy, or post-hoc explanation systems, that lack guarantees about their explanation quality. We propose an alternative to these approaches by directly regularizing a black-box model for interpretability at training time. Our approach explicitly connects three key aspects of interpretable machine learning: the model's innate explainability, the explanation system used at test time, and the metrics that measure explanation quality. Our regularization results in substantial (up to orders of magnitude) improvement in terms of explanation fidelity and stability metrics across a range of datasets, models, and black-box explanation systems. Remarkably, our regularizers also slightly improve predictive accuracy on average across the nine datasets we consider. Further, we show that the benefits of our novel regularizers on explanation quality provably generalize to unseen test points.