 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVM-based Deep Stacking Networks
Paper and Code
Feb 15, 2019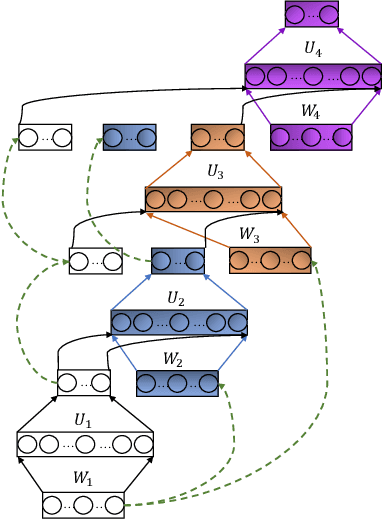
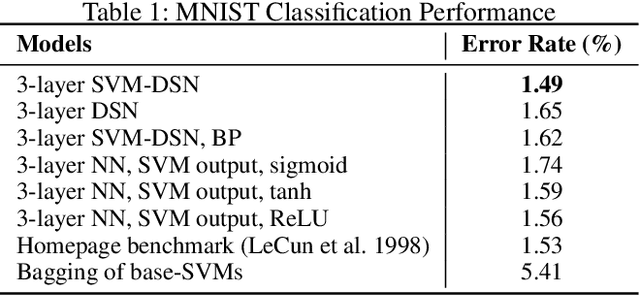
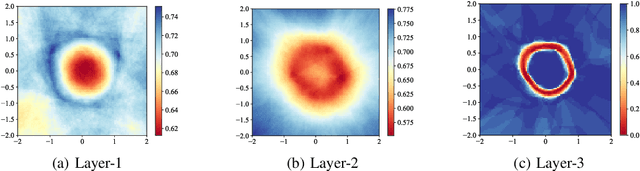
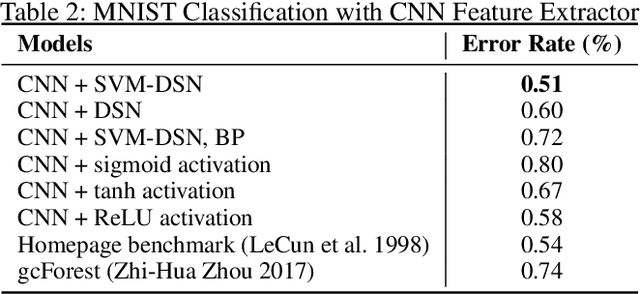
The deep network model, with the majority built on neural networks, has been proved to be a powerful framework to represent complex data for high performance machine learning. In recent years, more and more studies turn to nonneural network approaches to build diverse deep structures, and the Deep Stacking Network (DSN) model is one of such approaches that uses stacked easy-to-learn blocks to build a parameter-training-parallelizable deep network. In this paper, we propose a novel SVM-based Deep Stacking Network (SVM-DSN), which uses the DSN architecture to organize linear SVM classifiers for deep learning. A BP-like layer tuning scheme is also proposed to ensure holistic and local optimizations of stacked SVMs simultaneously. Some good math properties of SVM, such as the convex optimization, is introduced into the DSN framework by our model. From a global view, SVM-DSN can iteratively extract data representations layer by layer as a deep neural network but with parallelizability, and from a local view, each stacked SVM can converge to its optimal solution and obtain the support vectors, which compared with neural networks could lead to interesting improvements in anti-saturation and interpretability. Experimental results on both image and text data sets demonstrate the excellent performances of SVM-DSN compared with some competitive benchmark models.