 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Explanation for the Existence of Adversarial Examples with Small Hamming Distance
Paper and Code
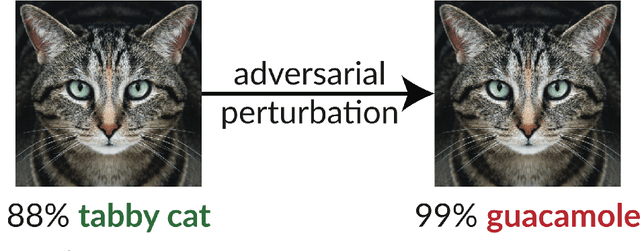

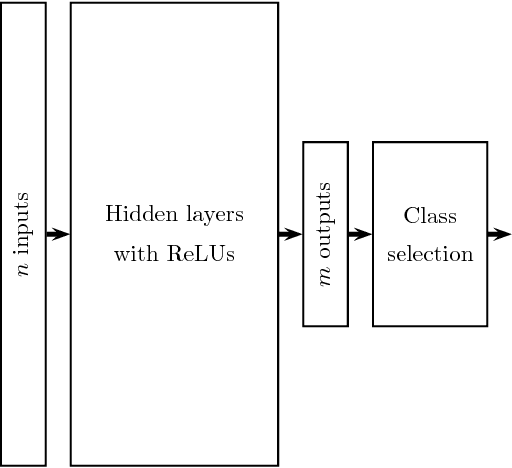
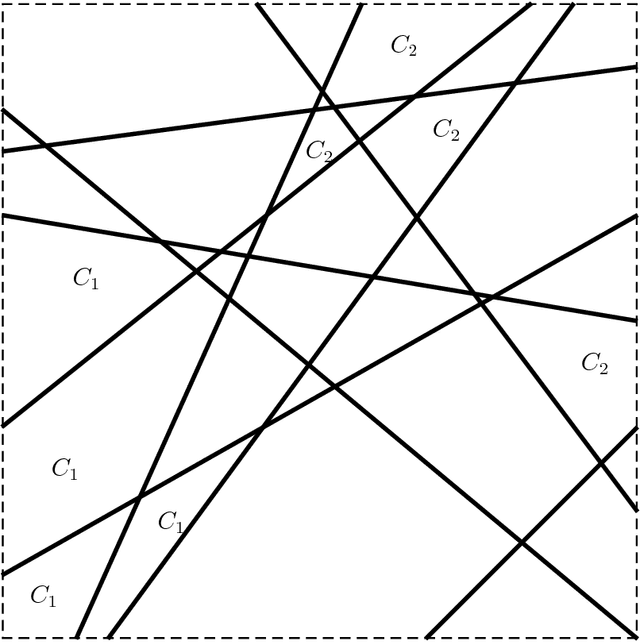
The existence of adversarial examples in which an imperceptible change in the input can fool well trained neural networks was experimentally discovered by Szegedy et al in 2013, who called them "Intriguing properties of neural networks". Since then, this topic had become one of the hottest research areas within machine learning, but the ease with which we can switch between any two decisions in targeted attacks is still far from being understood, and in particular it is not clear which parameters determine the number of input coordinates we have to change in order to mislead the network. In this paper we develop a simple mathematical framework which enables us to think about this baffling phenomenon from a fresh perspective, turning it into a natural consequence of the geometry of $\mathbb{R}^n$ with the $L_0$ (Hamming) metric, which can be quantitatively analyzed. In particular, we explain why we should expect to find targeted adversarial examples with Hamming distance of roughly $m$ in arbitrarily deep neural networks which are designed to distinguish between $m$ input classes.