 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugment your batch: better training with larger batches
Paper and Code
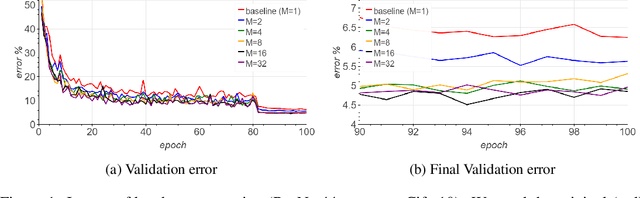
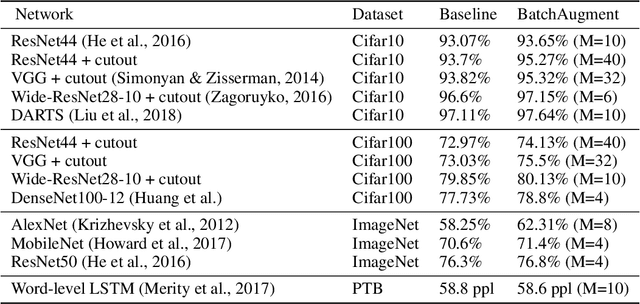
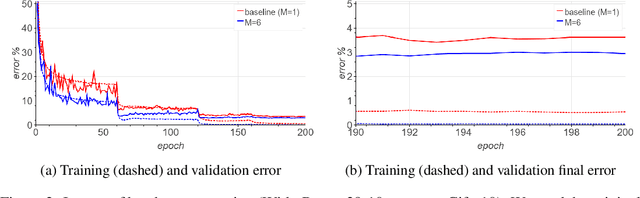

Large-batch SGD is important for scaling training of deep neural networks. However, without fine-tuning hyperparameter schedules, the generalization of the model may be hampered. We propose to use batch augmentation: replicating instances of samples within the same batch with different data augmentations. Batch augmentation acts as a regularizer and an accelerator, increasing both generalization and performance scaling. We analyze the effect of batch augmentation on gradient variance and show that it empirically improves convergence for a wide variety of deep neural networks and datasets. Our results show that batch augmentation reduces the number of necessary SGD updates to achieve the same accuracy as the state-of-the-art. Overall, this simple yet effective method enables faster training and better generalization by allowing more computational resources to be used concurrently.