 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Learning of Decentralized Control Policies for Articulated Mobile Robots
Paper and Code
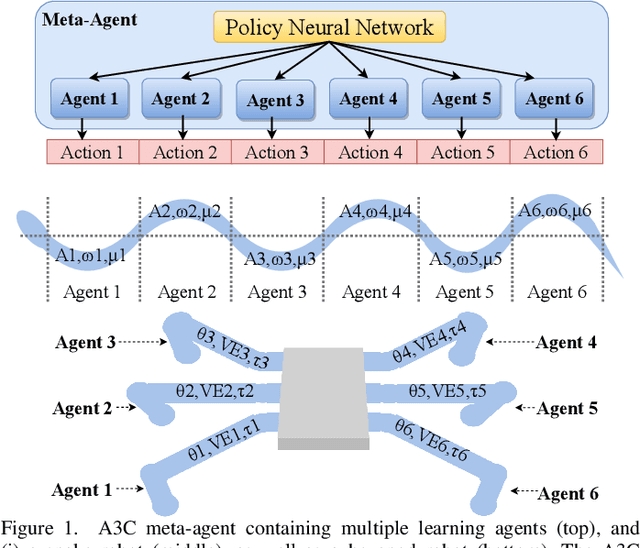
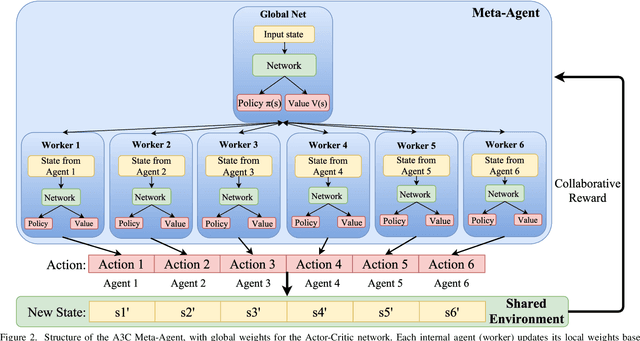
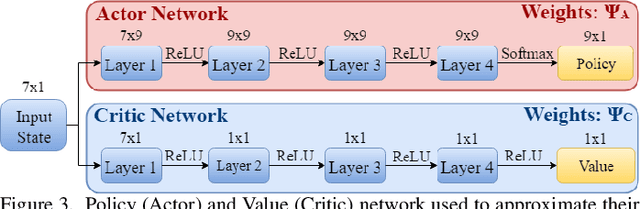
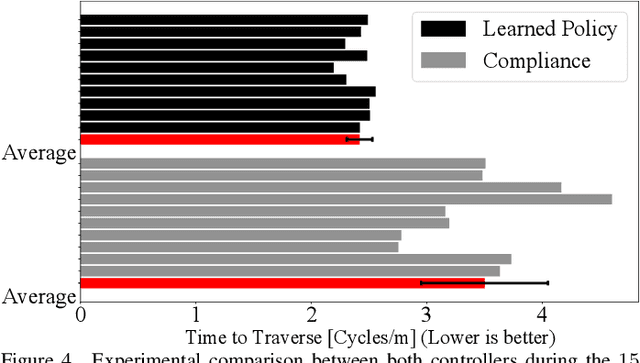
State-of-the-art distributed algorithms for reinforcement learning rely on multiple independent agents, which simultaneously learn in parallel environments while asynchronously updating a common, shared policy. Moreover, decentralized control architectures (e.g., CPGs) can coordinate spatially distributed portions of an articulated robot to achieve system-level objectives. In this work, we investigate the relationship between distributed learning and decentralized control by learning decentralized control policies for the locomotion of articulated robots in challenging environments. To this end, we present an approach that leverages the structure of the asynchronous advantage actor-critic (A3C) algorithm to provide a natural means of learning decentralized control policies on a single articulated robot. Our primary contribution shows individual agents in the A3C algorithm can be defined by independently controlled portions of the robot's body, thus enabling distributed learning on a single robot for efficient hardware implementation. We present results of closed-loop locomotion in unstructured terrains on a snake and a hexapod robot, using decentralized controllers learned offline and online respectively. Preprint of the paper submitted to the IEEE Transactions in Robotics (T-RO) journal in October 2018, and conditionally accepted for publication as a regular paper in January 2019.