 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Subspace Clustering and Cluster Number Estimating based on Triplet Relationship
Paper and Code
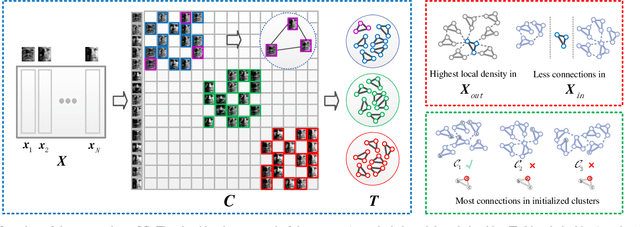
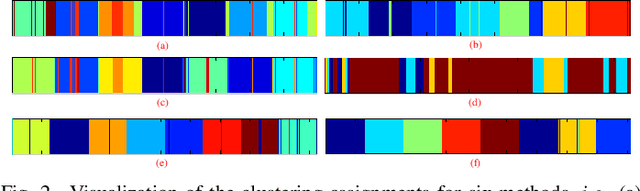
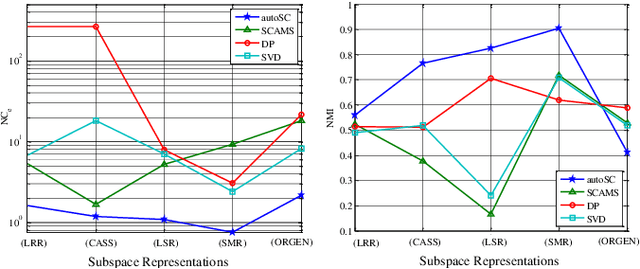
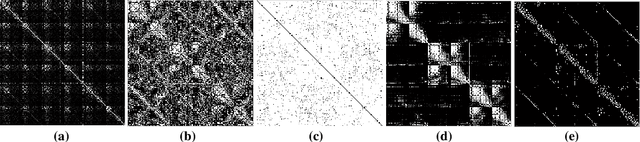
In this paper we propose a unified framework to simultaneously discover the number of clusters and group the data points into them using subspace clustering. Real data distributed in a high-dimensional space can be disentangled into a union of low-dimensional subspaces, which can benefit various applications. To explore such intrinsic structure, state-of-the-art subspace clustering approaches often optimize a self-representation problem among all samples, to construct a pairwise affinity graph for spectral clustering. However, a graph with pairwise similarities lacks robustness for segmentation, especially for samples which lie on the intersection of two subspaces. To address this problem, we design a hyper-correlation based data structure termed as the \textit{triplet relationship}, which reveals high relevance and local compactness among three samples. The triplet relationship can be derived from the self-representation matrix, and be utilized to iteratively assign the data points to clusters. Three samples in each triplet are encouraged to be highly correlated and are considered as a meta-element during clustering, which show more robustness than pairwise relationships when segmenting two densely distributed subspaces. Based on the triplet relationship, we propose a unified optimizing scheme to automatically calculate clustering assignments. Specifically, we optimize a model selection reward and a fusion reward by simultaneously maximizing the similarity of triplets from different clusters while minimizing the correlation of triplets from same cluster. The proposed algorithm also automatically reveals the number of clusters and fuses groups to avoid over-segmentation. Extensive experimental results on both synthetic and real-world datasets validate the effectiveness and robustness of the proposed method.