 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building the Semantic Map from a Monocular Camera with a Multi-task Network
Paper and Code
Jan 17, 2019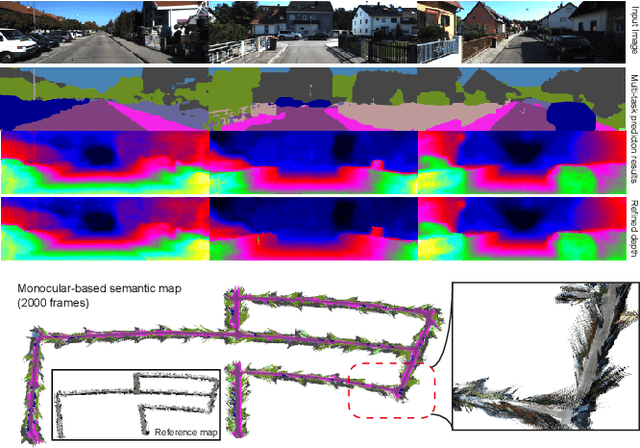
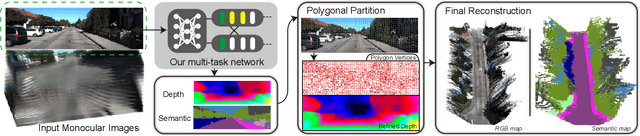
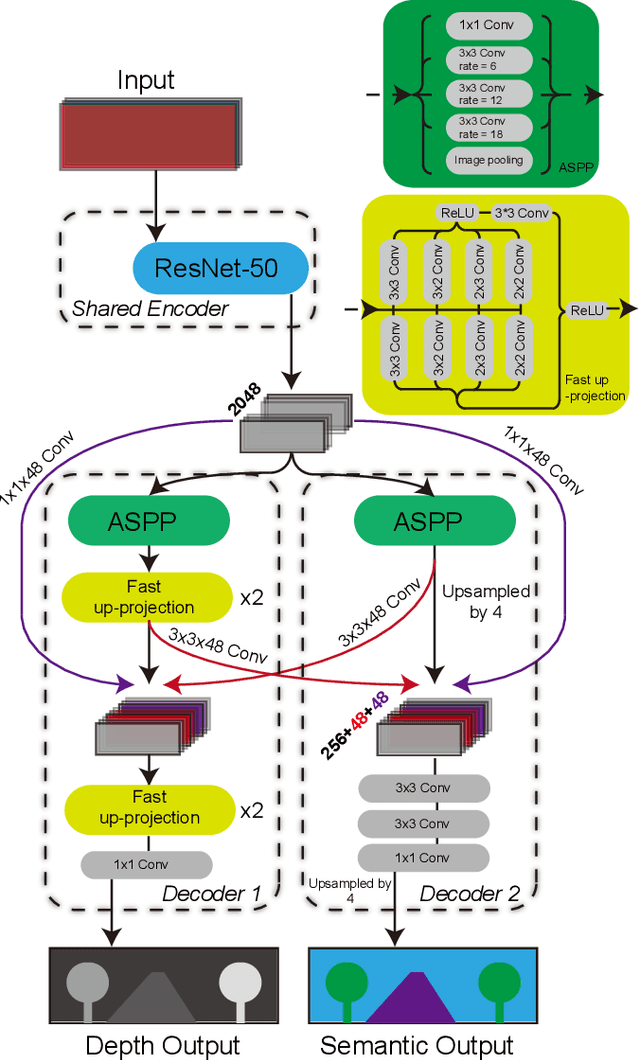
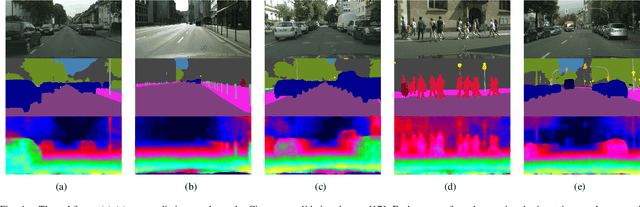
In many robotic applications, especially for the autonomous driving, understanding the semantic information and the geometric structure of surroundings are both essential. Semantic 3D maps, as a carrier of the environmental knowledge, are then intensively studied for their abilities and applications. However, it is still challenging to produce a dense outdoor semantic map from a monocular image stream. Motivated by this target, in this paper, we propose a method for large-scale 3D reconstruction from consecutive monocular images. First, with the correlation of underlying information between depth and semantic prediction, a novel multi-task Convolutional Neural Network (CNN) is designed for joint prediction. Given a single image, the network learns low-level information with a shared encoder and separately predicts with decoders containing additional Atrous Spatial Pyramid Pooling (ASPP) layers and the residual connection which merits disparities and semantic mutually. To overcome the inconsistency of monocular depth prediction for reconstruction, post-processing steps with the superpixelization and the effective 3D representation approach are obtained to give the final semantic map. Experiments are compared with other methods on both semantic labeling and depth prediction. We also qualitatively demonstrate the map reconstructed from large-scale, difficult monocular image sequences to prove the effectiveness and superiority.