 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataflow-based Joint Quantization of Weights and Activations for Deep Neural Networks
Paper and Code
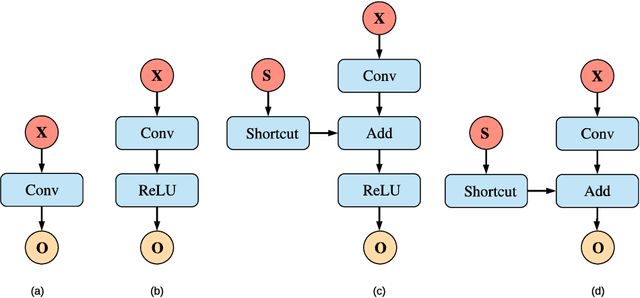



This paper addresses a challenging problem - how to reduce energy consumption without incurring performance drop when deploying deep neural networks (DNNs) at the inference stage. In order to alleviate the computation and storage burdens, we propose a novel dataflow-based joint quantization approach with the hypothesis that a fewer number of quantization operations would incur less information loss and thus improve the final performance. It first introduces a quantization scheme with efficient bit-shifting and rounding operations to represent network parameters and activations in low precision. Then it restructures the network architectures to form unified modules for optimization on the quantized model. Extensive experiments on ImageNet and KITTI validate the effectiveness of our model, demonstrating that state-of-the-art results for various tasks can be achieved by this quantized model. Besides, we designed and synthesized an RTL model to measure the hardware costs among various quantization methods. For each quantization operation, it reduces area cost by about 15 times and energy consumption by about 9 times, compared to a strong baseline.