 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving large-scale L1-regularized SVMs and cousins: the surprising effectiveness of column and constraint generation
Paper and Code
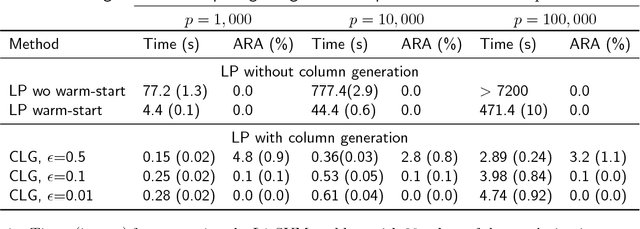
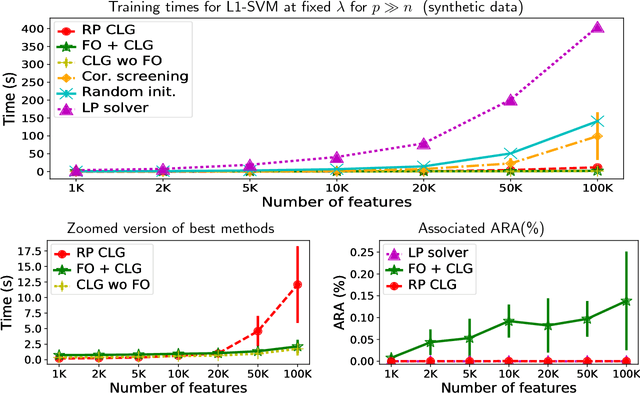
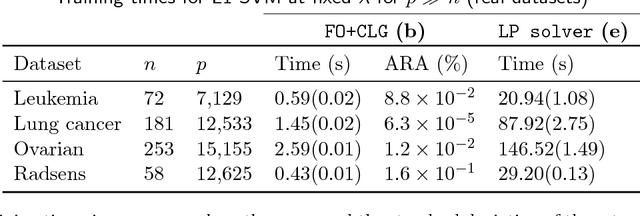
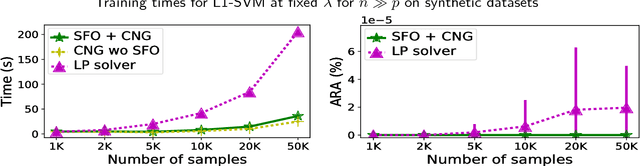
The linear Support Vector Machine (SVM) is one of the most popular binary classification techniques in machine learning. Motivated by applications in modern high dimensional statistics, we consider penalized SVM problems involving the minimization of a hinge-loss function with a convex sparsity-inducing regularizer such as: the L1-norm on the coefficients, its grouped generalization and the sorted L1-penalty (aka Slope). Each problem can be expressed as a Linear Program (LP) and is computationally challenging when the number of features and/or samples is large -- the current state of algorithms for these problems is rather nascent when compared to the usual L2-regularized linear SVM. To this end, we propose new computational algorithms for these LPs by bringing together techniques from (a) classical column (and constraint) generation methods and (b) first order methods for non-smooth convex optimization - techniques that are rarely used together for solving large scale LPs. These components have their respective strengths; and while they are found to be useful as separate entities, they have not been used together in the context of solving large scale LPs such as the ones studied herein. Our approach complements the strengths of (a) and (b) --- leading to a scheme that seems to outperform commercial solvers as well as specialized implementations for these problems by orders of magnitude. We present numerical results on a series of real and synthetic datasets demonstrating the surprising effectiveness of classic column/constraint generation methods in the context of challenging LP-based machine learning tasks.