 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning at the Wireless Edge: Distributed Stochastic Gradient Descent Over-the-Air
Paper and Code
Jan 03, 2019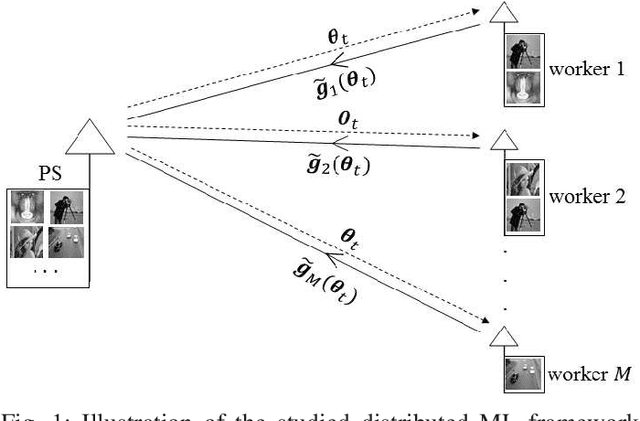
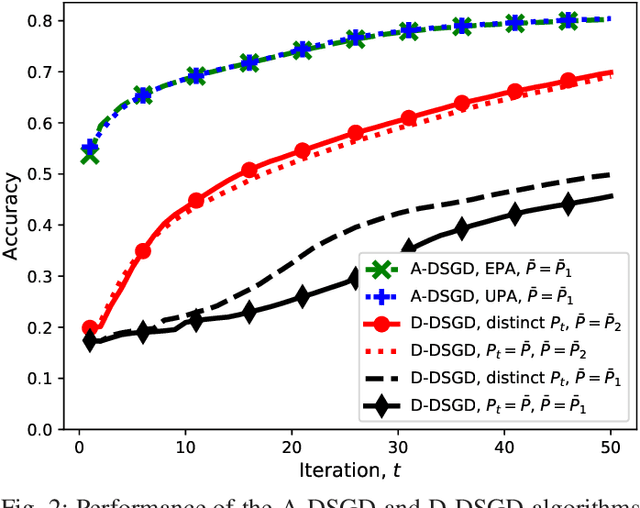
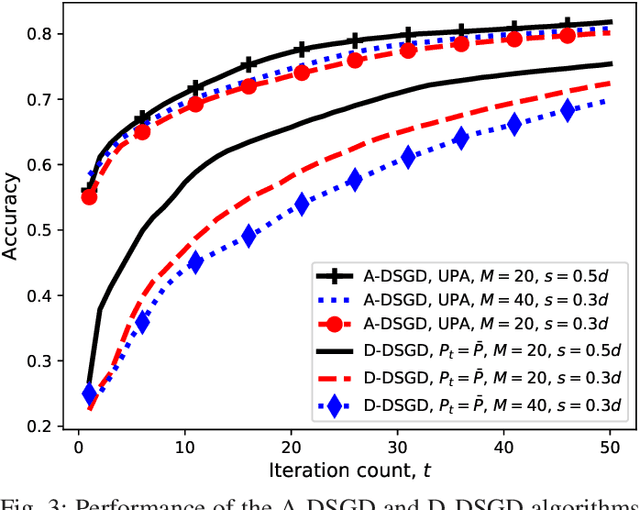
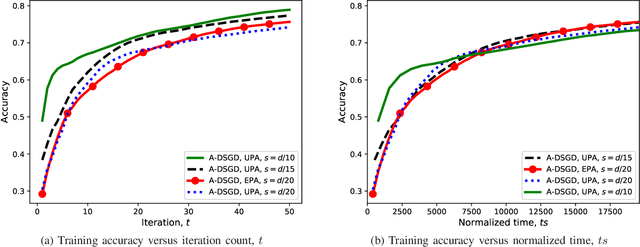
We study collaborative machine learning at the wireless edge, where power and bandwidth-limited devices (workers), with limited local datasets, implement distributed stochastic gradient descent (DSGD) over-the-air with the help of a parameter server (PS). Standard approaches inherently assume separate computation and communication, where local gradient estimates are compressed and communicated to the PS over the wireless multiple access channel (MAC). Following this digital approach, we introduce D-DSGD, assuming that the workers operate on the boundary of the MAC capacity region at each iteration of the DSGD algorithm, and employ gradient quantization and error accumulation to transmit their gradient estimates within the bit budget allowed by the employed power allocation. We then introduce an analog scheme, called A-DSGD, motivated by the additive nature of the wireless MAC. In A-DSGD, the workers first sparsify their gradient estimates (with error accumulation), and then project them to a lower dimensional space imposed by the available channel bandwidth. These projections are transmitted directly over the MAC without employing any digital code. Numerical results show that A-DSGD converges much faster than D-DSGD thanks to its more efficient use of the limited bandwidth and the natural alignment of the gradient estimates over the MAC. The improvement is particularly compelling at low power and low bandwidth regimes. We also observe that the performance of A-DSGD improves with the number of workers, while D-DSGD deteriorates, limiting the ability of the latter in harnessing the computation power of too many edge devices. We highlight that the lack of quantization and channel encoding/decoding operations in A-DSGD further speeds up communication, making it very attractive for low-latency machine learning applications at the wireless network edge.