 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeATHENA: Automated Tuning of Genomic Error Correction Algorithms using Language Models
Paper and Code
Dec 30, 2018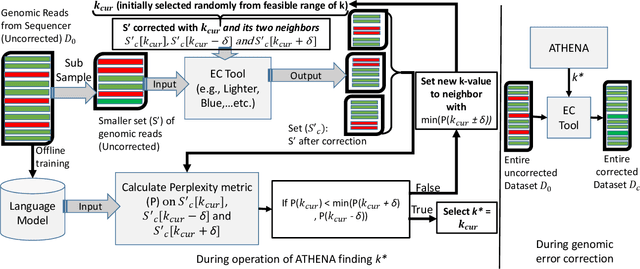


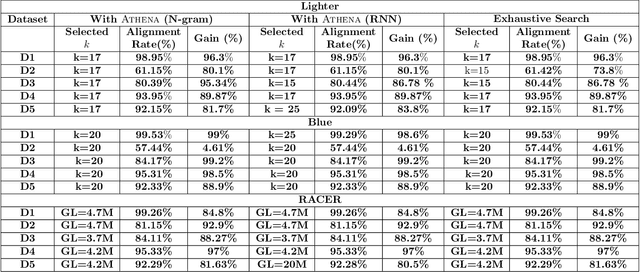
The performance of most error-correction algorithms that operate on genomic sequencer reads is dependent on the proper choice of its configuration parameters, such as the value of k in k-mer based techniques. In this work, we target the problem of finding the best values of these configuration parameters to optimize error correction. We perform this in a data-driven manner, due to the observation that different configuration parameters are optimal for different datasets, i.e., from different instruments and organisms. We use language modeling techniques from the Natural Language Processing (NLP) domain in our algorithmic suite, Athena, to automatically tune the performance-sensitive configuration parameters. Through the use of N-Gram and Recurrent Neural Network (RNN) language modeling, we validate the intuition that the EC performance can be computed quantitatively and efficiently using the perplexity metric, prevalent in NLP. After training the language model, we show that the perplexity metric calculated for runtime data has a strong negative correlation with the correction of the erroneous NGS reads. Therefore, we use the perplexity metric to guide a hill climbing-based search, converging toward the best $k$-value. Our approach is suitable for both de novo and comparative sequencing (resequencing), eliminating the need for a reference genome to serve as the ground truth. This is important because the use of a reference genome often carries forward the biases along the stages of the pipeline.