 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainability by Parsing: Neural Module Tree Networks for Natural Language Visual Grounding
Paper and Code
Dec 08, 2018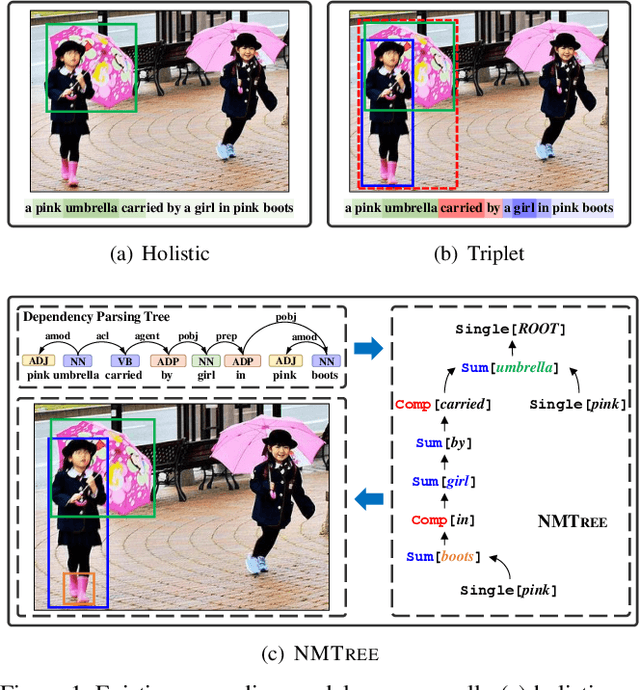
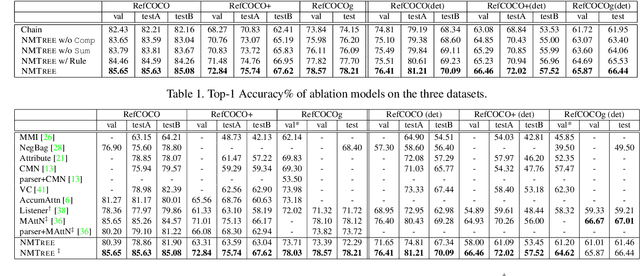
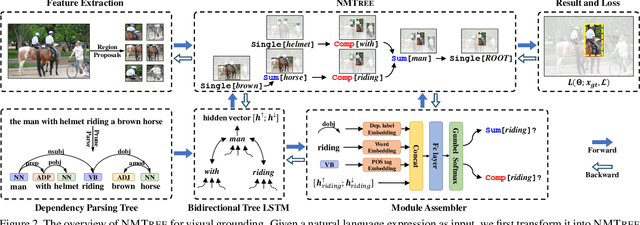

Grounding natural language in images essentially requires composite visual reasoning. However, existing methods over-simplify the composite nature of language into a monolithic sentence embedding or a coarse composition of subject-predicate-object triplet. They might perform well on short phrases, but generally fail in longer sentences, mainly due to the over-fitting to certain vision-language bias. In this paper, we propose to ground natural language in an intuitive, explainable, and composite fashion as it should be. In particular, we develop a novel modular network called Neural Module Tree network (NMTree) that regularizes the visual grounding along the dependency parsing tree of the sentence, where each node is a module network that calculates or accumulates the grounding score in a bottom-up direction where as needed. NMTree disentangles the visual grounding from the composite reasoning, allowing the former to only focus on primitive and easy-to-generalize patterns. To reduce the impact of parsing errors, we train the modules and their assembly end-to-end by using the Gumbel-Softmax approximation and its straight-through gradient estimator, accounting for the discrete process of module selection. Overall, the proposed NMTree not only consistently outperforms the state-of-the-arts on several benchmarks and tasks, but also shows explainable reasoning in grounding score calculation. Therefore, NMTree shows a good direction in closing the gap between explainability and performance.