 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Distribution in Neighborhood for Classification
Paper and Code
Dec 07, 2018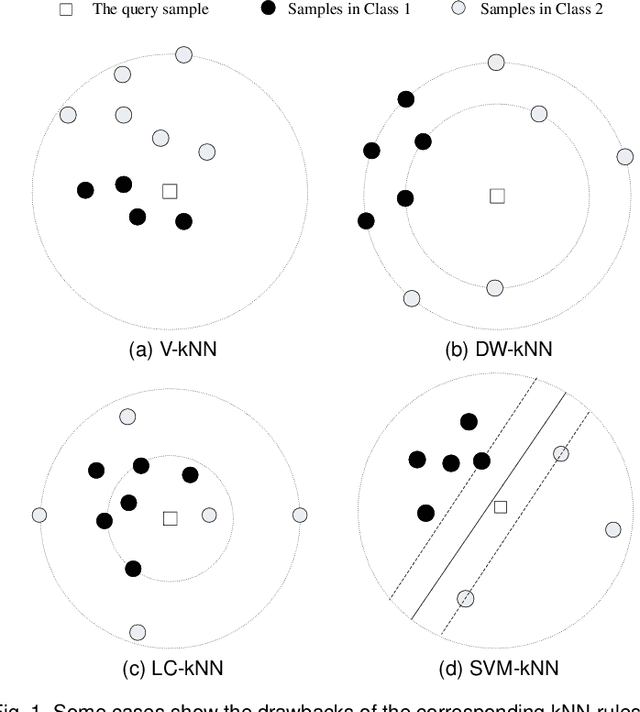
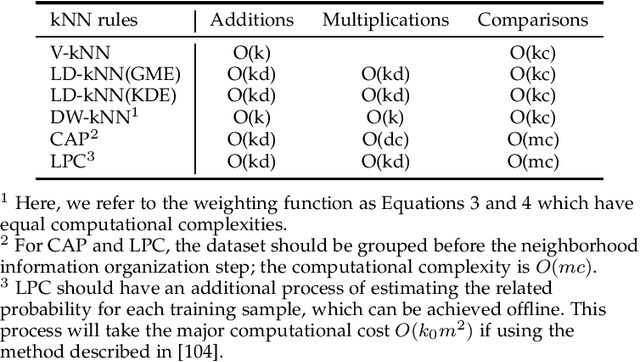
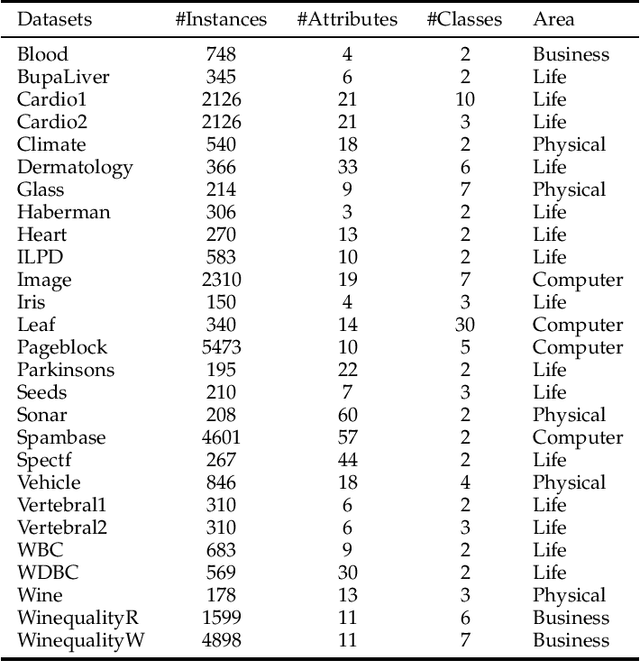
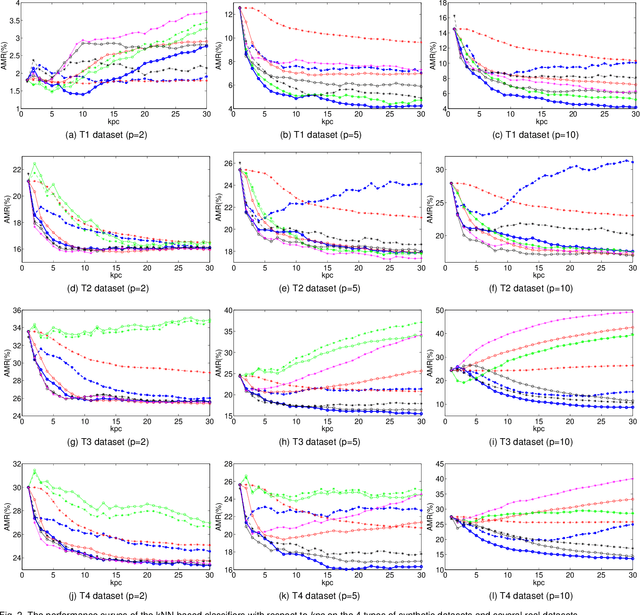
The k-nearest-neighbor method performs classification tasks for a query sample based on the information contained in its neighborhood. Previous studies into the k-nearest-neighbor algorithm usually achieved the decision value for a class by combining the support of each sample in the neighborhood. They have generally considered the nearest neighbors separately, and potentially integral neighborhood information important for classification was lost, e.g. the distribution information. This article proposes a novel local learning method that organizes the information in the neighborhood through local distribution. In the proposed method, additional distribution information in the neighborhood is estimated and then organized; the classification decision is made based on maximum posterior probability which is estimated from the local distribution in the neighborhood. Additionally, based on the local distribution, we generate a generalized local classification form that can be effectively applied to various datasets through tuning the parameters. We use both synthetic and real datasets to evaluate the classification performance of the proposed method; the experimental results demonstrate the dimensional scalability, efficiency, effectiveness and robustness of the proposed method compared to some other state-of-the-art classifiers. The results indicate that the proposed method is effective and promising in a broad range of domains.