 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Security and Privacy Analytics via Collective Classification with Joint Weight Learning and Propagation
Paper and Code
Dec 06, 2018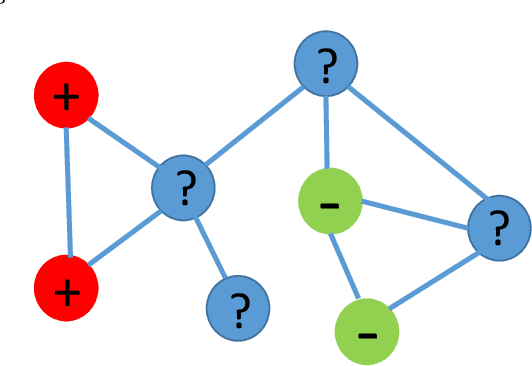
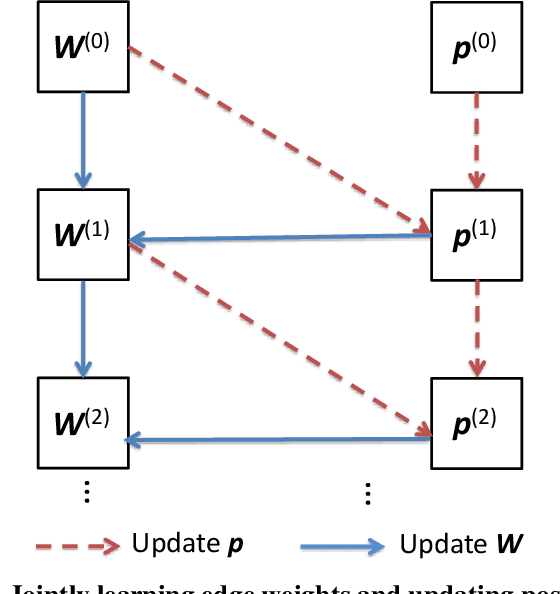
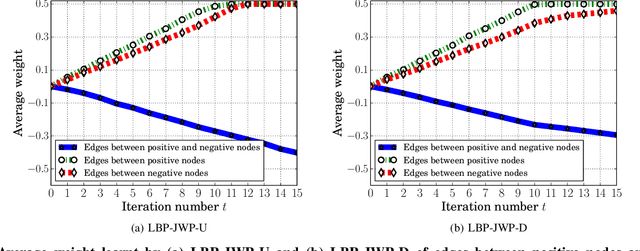
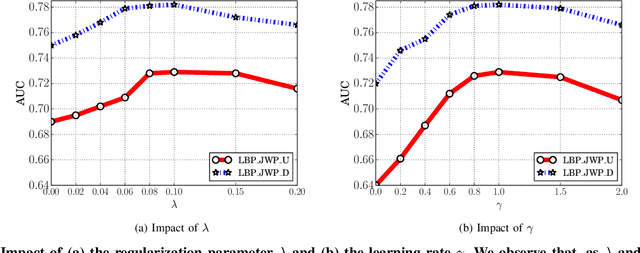
Many security and privacy problems can be modeled as a graph classification problem, where nodes in the graph are classified by collective classification simultaneously. State-of-the-art collective classification methods for such graph-based security and privacy analytics follow the following paradigm: assign weights to edges of the graph, iteratively propagate reputation scores of nodes among the weighted graph, and use the final reputation scores to classify nodes in the graph. The key challenge is to assign edge weights such that an edge has a large weight if the two corresponding nodes have the same label, and a small weight otherwise. Although collective classification has been studied and applied for security and privacy problems for more than a decade, how to address this challenge is still an open question. In this work, we propose a novel collective classification framework to address this long-standing challenge. We first formulate learning edge weights as an optimization problem, which quantifies the goals about the final reputation scores that we aim to achieve. However, it is computationally hard to solve the optimization problem because the final reputation scores depend on the edge weights in a very complex way. To address the computational challenge, we propose to jointly learn the edge weights and propagate the reputation scores, which is essentially an approximate solution to the optimization problem. We compare our framework with state-of-the-art methods for graph-based security and privacy analytics using four large-scale real-world datasets from various application scenarios such as Sybil detection in social networks, fake review detection in Yelp, and attribute inference attacks. Our results demonstrate that our framework achieves higher accuracies than state-of-the-art methods with an acceptable computational overhead.